STL-源码剖析(侯捷)
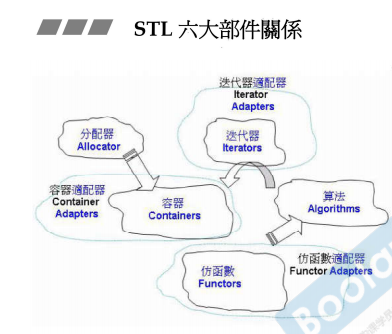
模板知识
|
|
编译器会对模板函数进行实参推导。
Specialization 特化
对某种特定的类型,可以给一个特定的函数。
|
|
STL 源代码中
|
|
Partial Specialization 偏特化
类似于偏微分。第一种:
|
|
对多个模板中的某个模板进行特化,为第一种偏特化。
第二种偏特化:范围的偏特化。
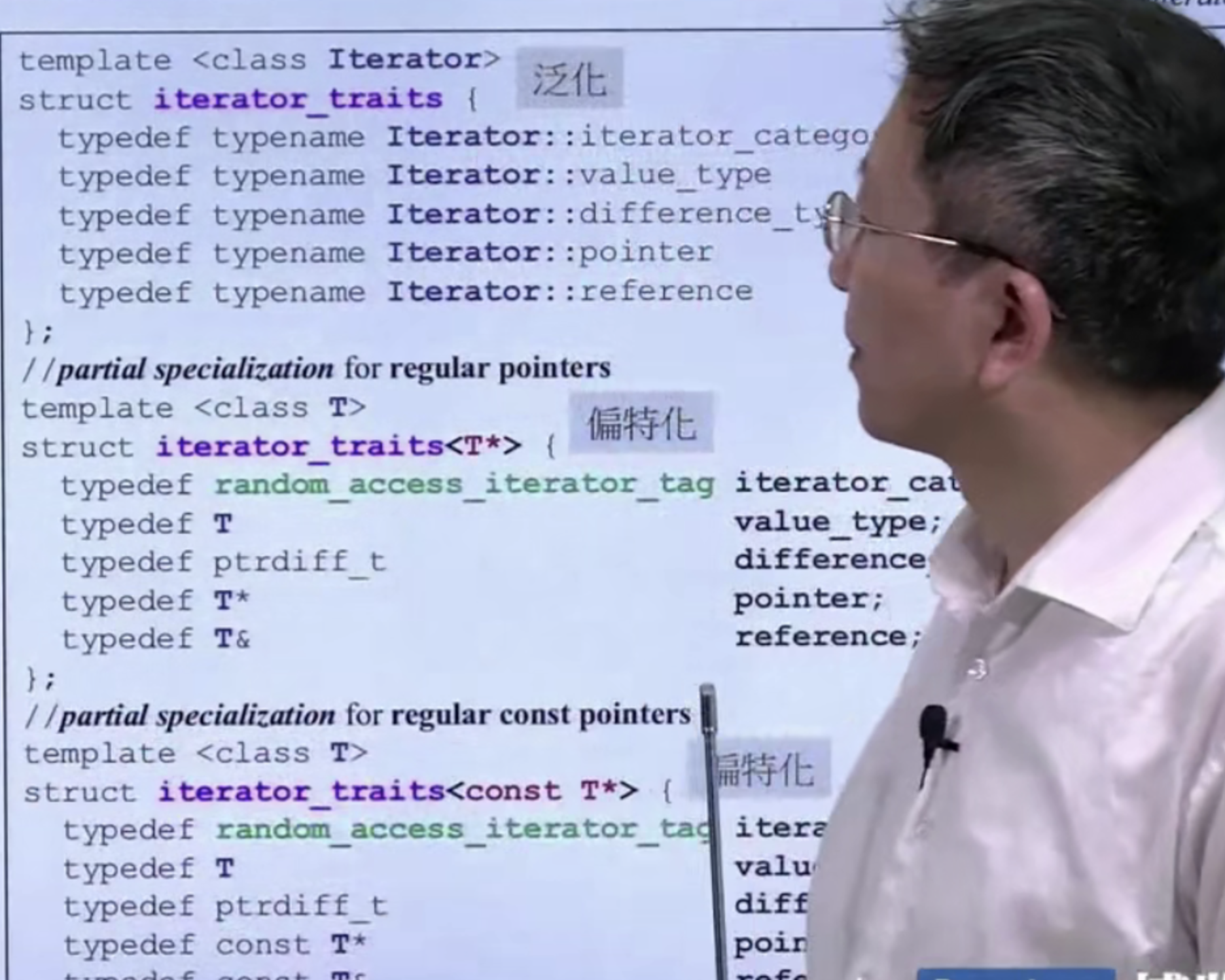
上面例子对 T 为指针时做了偏特化,常量指针又做了偏特化。
分配器 allocators
分配器扮演的是幕后英雄的角色。
operator new 和 malloc

new 的底部其实是调用了 malloc。
allocator
VC6,GCC和 BC5 的 allocator 只是用 new 和 delete 的重载完成了 allocate()和 deallocate(),没有其他特殊设计。
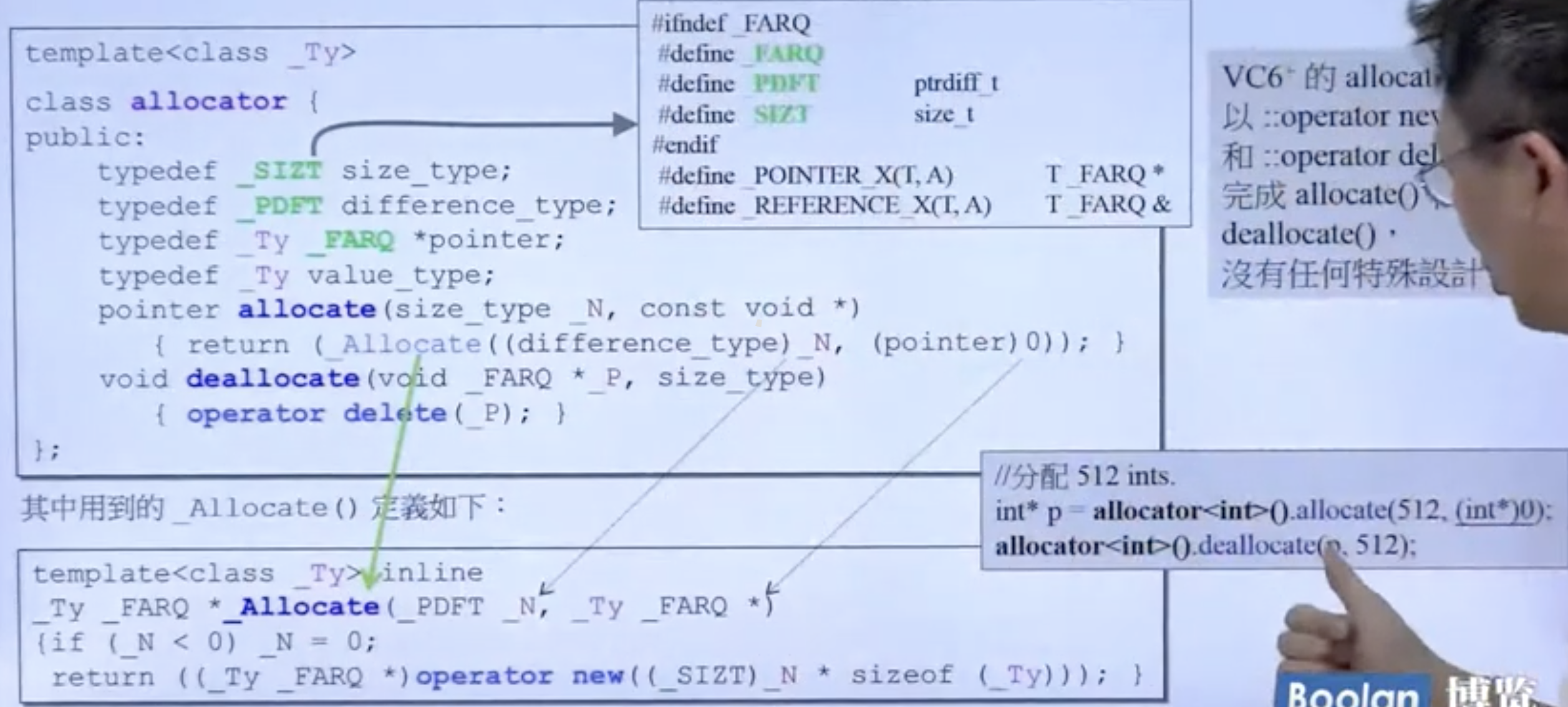
可以自己尝试去调用:
|
|
这里要求使用者知道当初申请了多少单位的内存,而容器调用时则不会出现这种问题。
所有的容器用的都是这种分配器。若无数元素都是使用new ,将会消耗大量的格外空间,造成浪费。

GCC 中说明,虽然做出了这个分配器,但是自己的容器都不使用它。
alloc
GCC 2.9.1实际上默认的 alloc:
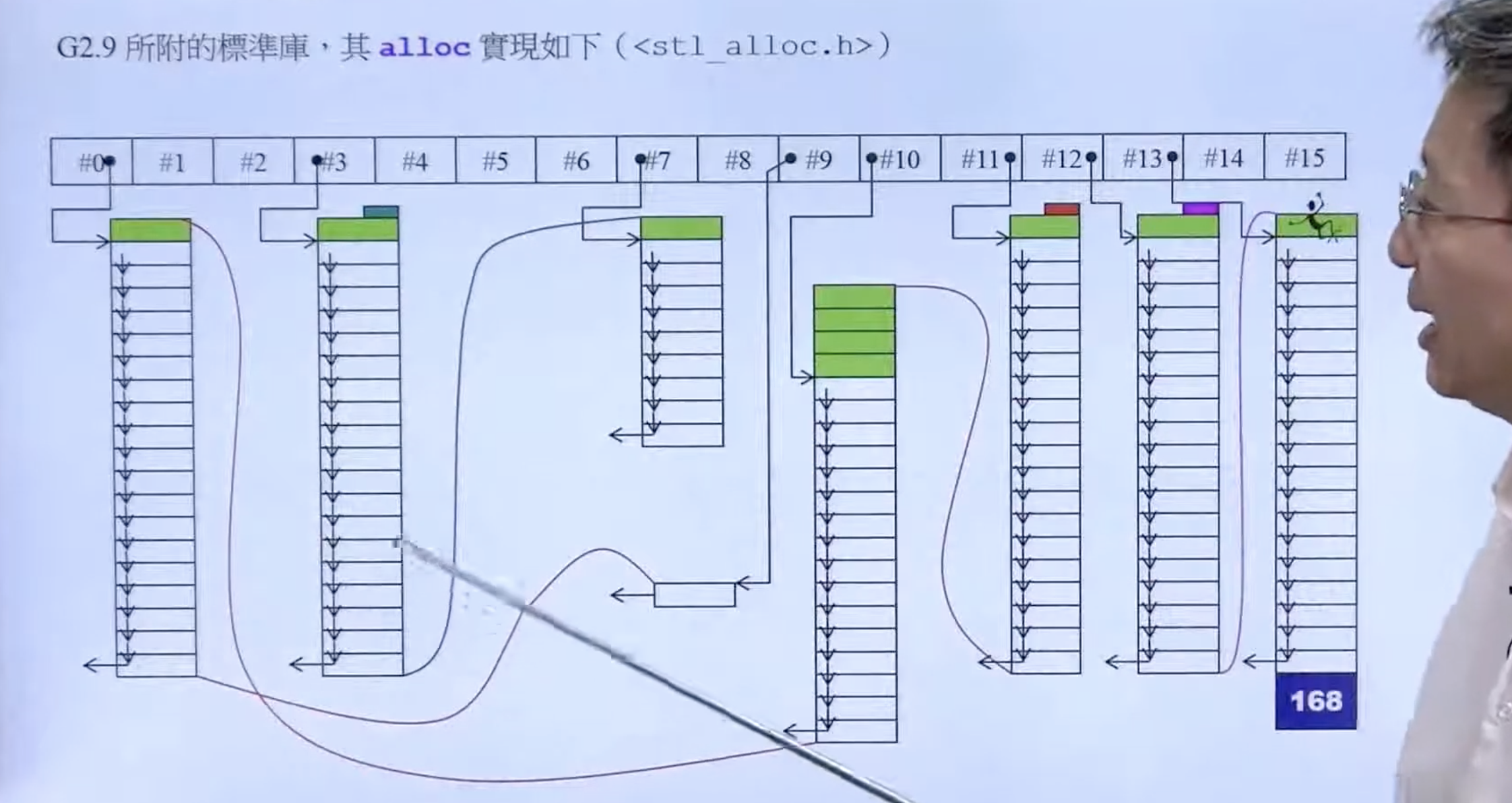
主要诉求是,减少 malloc 的次数。这样可以减少 cookies,还有内存对齐带来的浪费。 容器的大小按 8 的倍数来分配。第一个链表负责 8byte,第二个负责 16byte,第三个负责 24byte。。。当链表的内存用完后,再借用其他链表的内存,连接起来。这样减少了 cookies。
但是 GCC4.9使用的又变回了没有特殊设计的 allocator。alloc 的名称也被变为__pool_alloc。
容器 container 和 迭代器 iterator
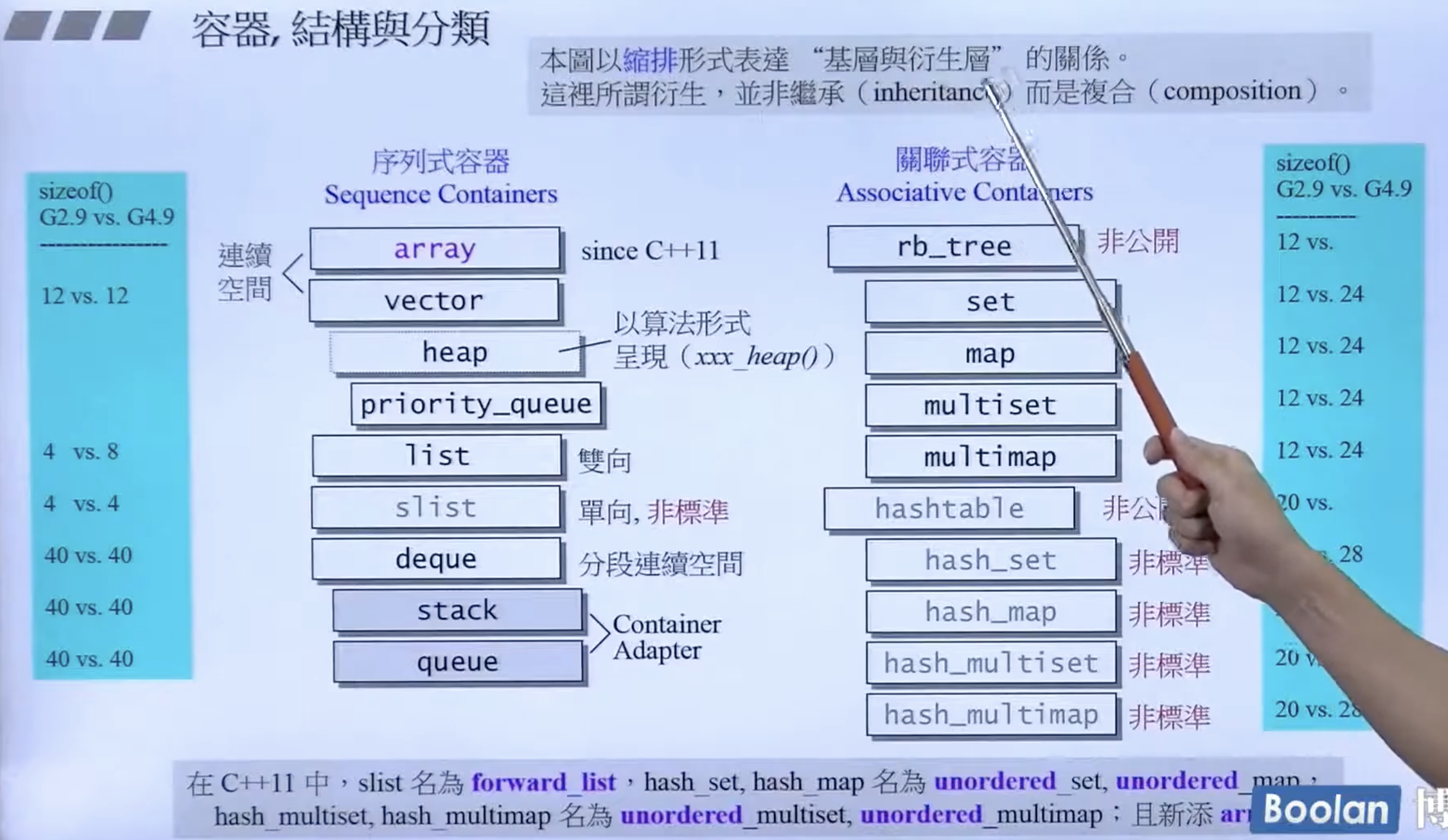
红黑树是 set、map 的底层。vector 支撑了 heap,heap 支撑了 priority_queue。deque 支撑了 stack 和 queue。unordered_ 类的底层都是 hashtable。
这里的关系是组合而非继承。
list 链表
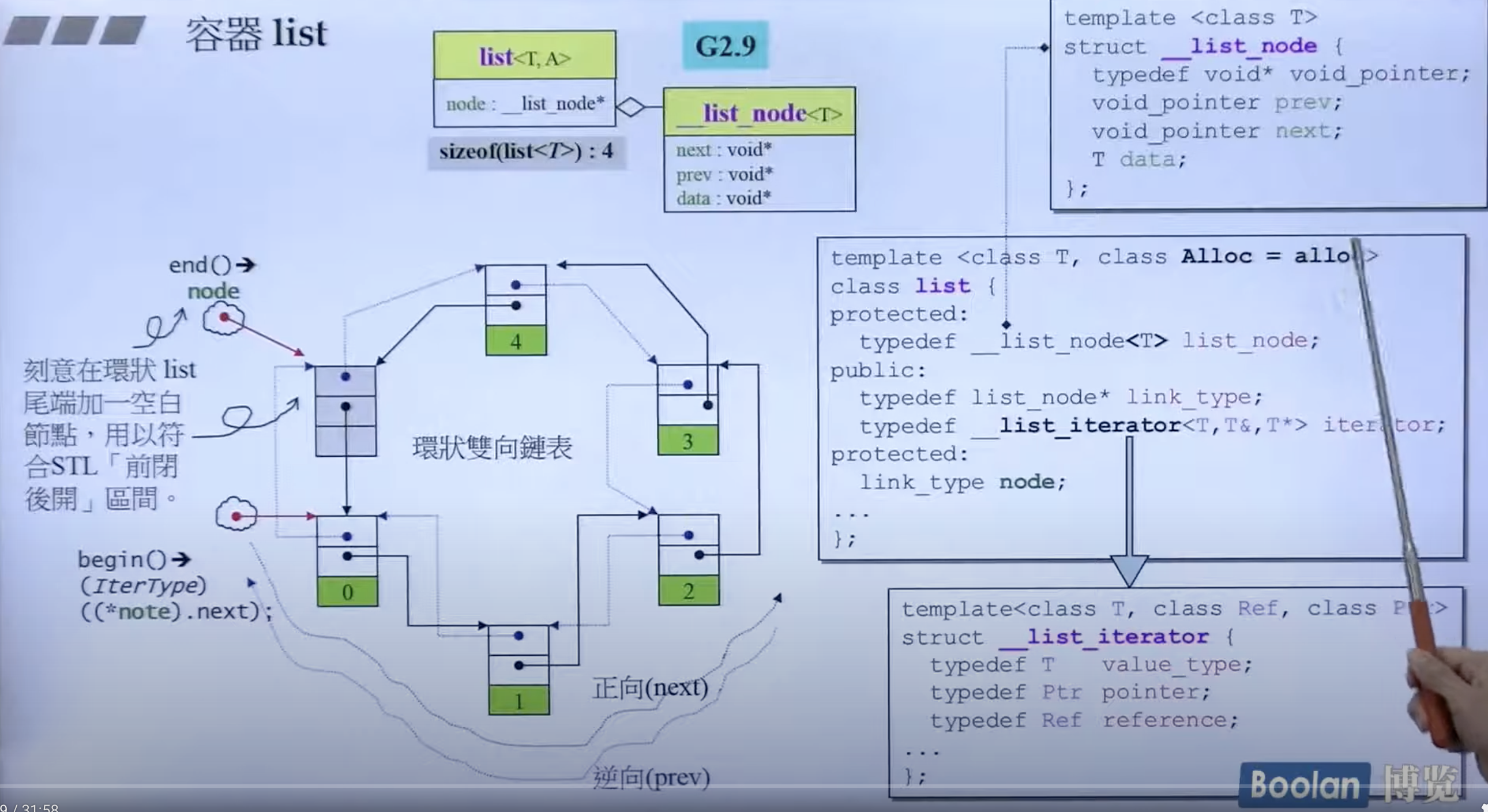
list_node 是平时的节点,list 包含一个 list_node 的指针。一个 list_node 除了数据,还有两个指针。
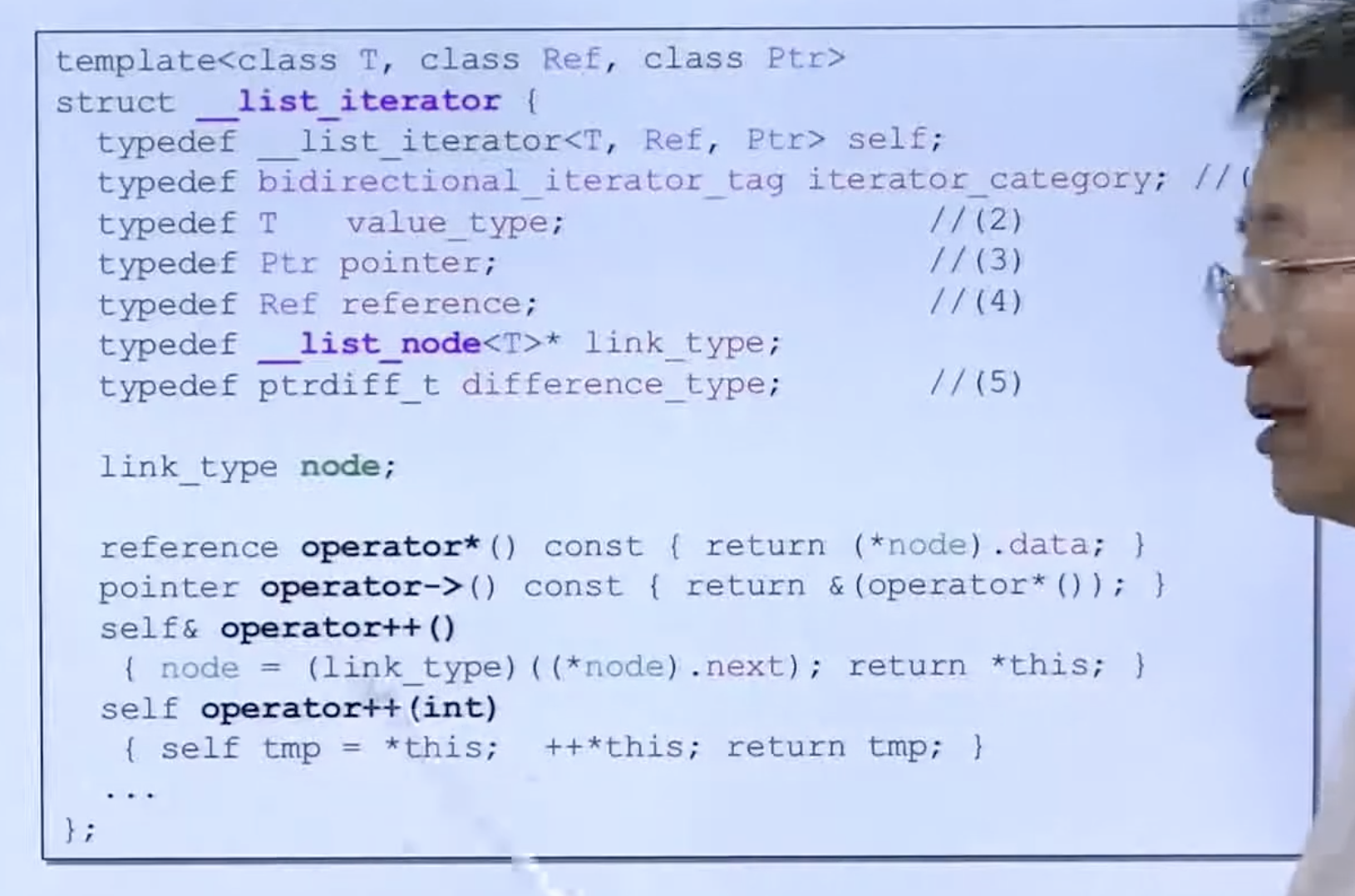
__list_iterator
iterator:希望它模拟指针的动作,因而会取到 list_node 中的 next 中去。
|
|
++的实现:


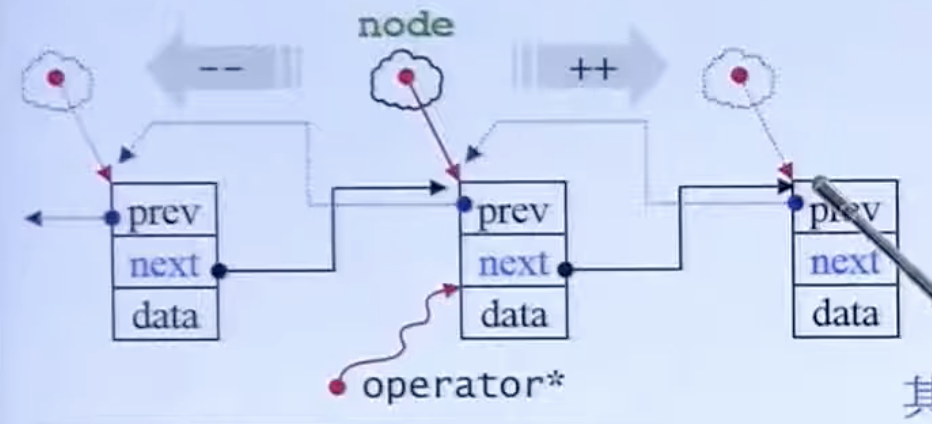
注意这里跟整数一样,i++++或 (i++)++都是非法操作。所以返回是否为引用,也很讲究。
*号:取得 data的引用;→号:取得本身操作对象数据地址。


GCC4.9的改进
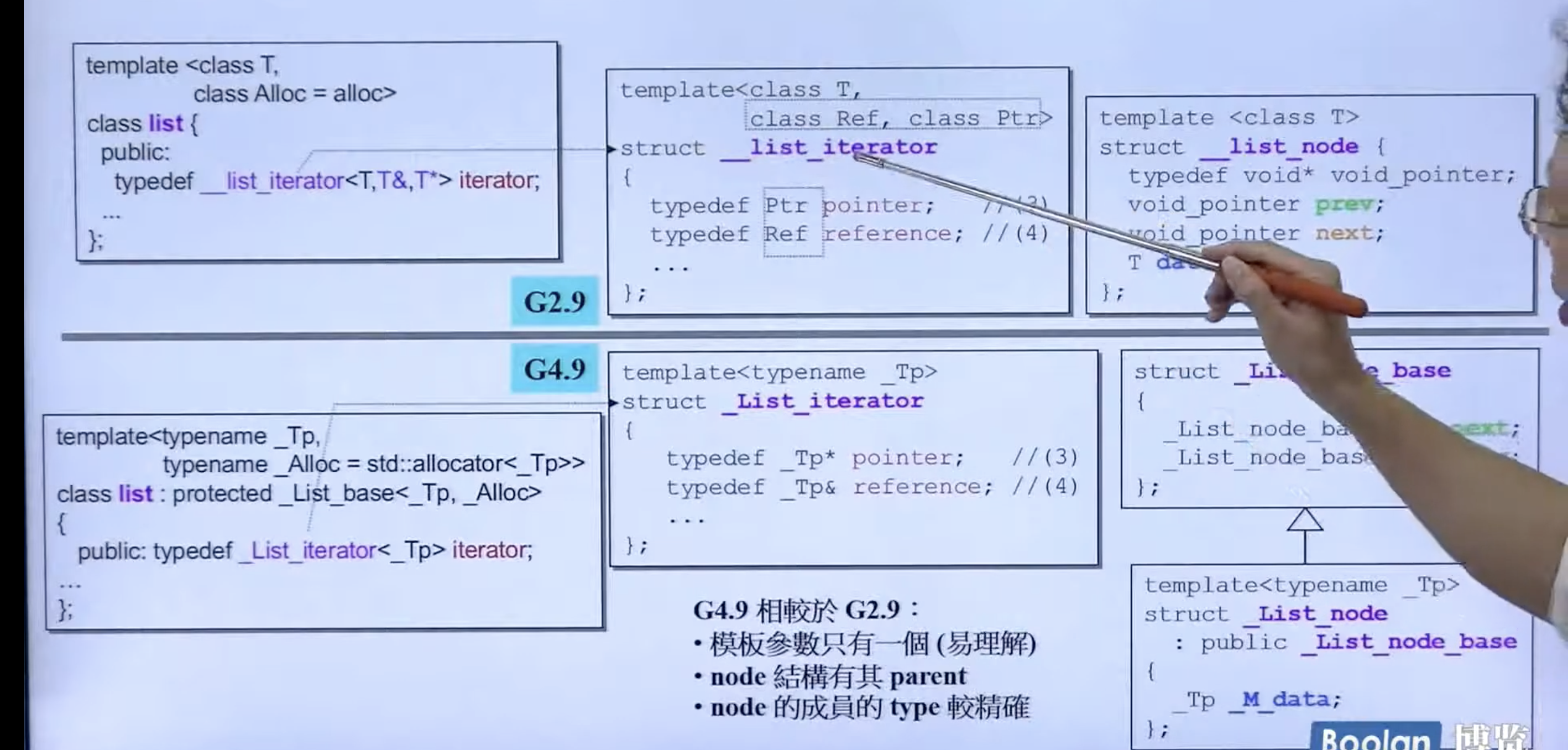
iterator 只保留了一个模板参数,更好。节点本身的 prev 和 next 不再是 void*,更好。
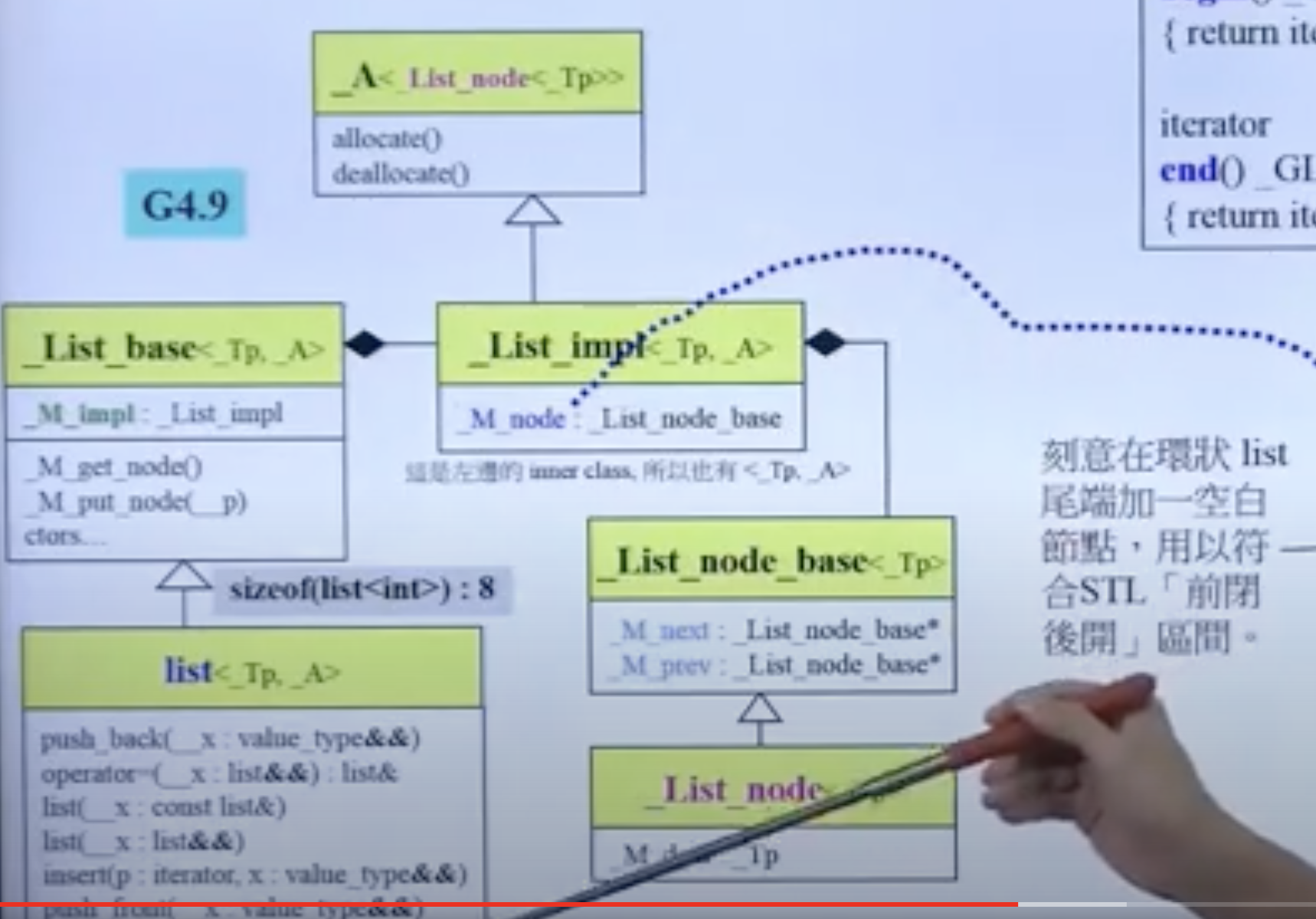
但是也变得更复杂。新版的 list 多了一个指向最后空白节点的指针,大小变为 8。
iterator 迭代器的特征
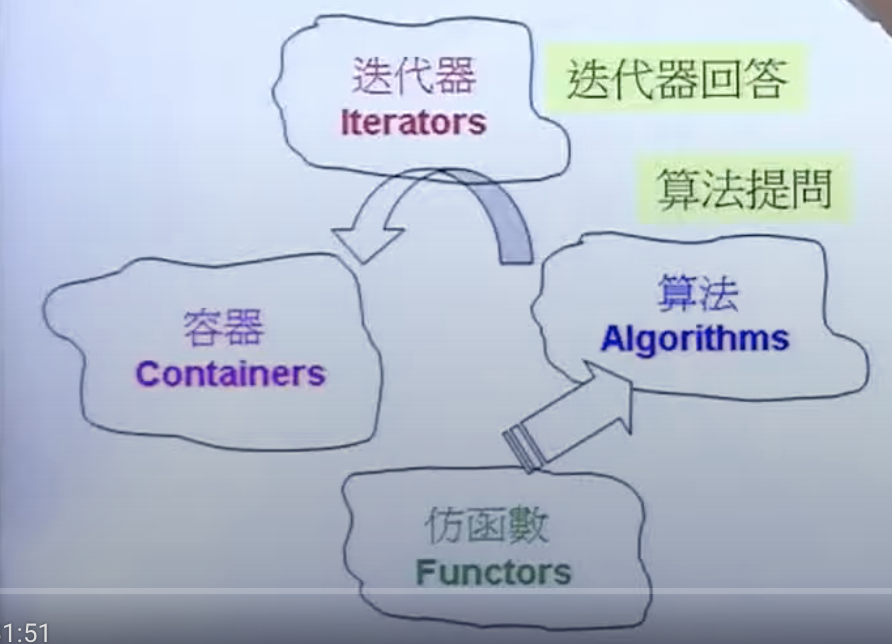
迭代器回答算法关于数据的一些性质,从而启示算法如何去执行。如算法 rotate:

上面反映的三种回答:
- iterator_category 迭代器的分类:如是否可以+=3,是否可以两向移动。。。
- value_type 数据的类型
- difference_type 两个数据之间距离的类型。
另外还有两种:
- reference_type
- pointer_type
后面两种从来没有被使用过。

但若单纯的指针作为迭代器时,就需要萃取(Traits)了。
萃取
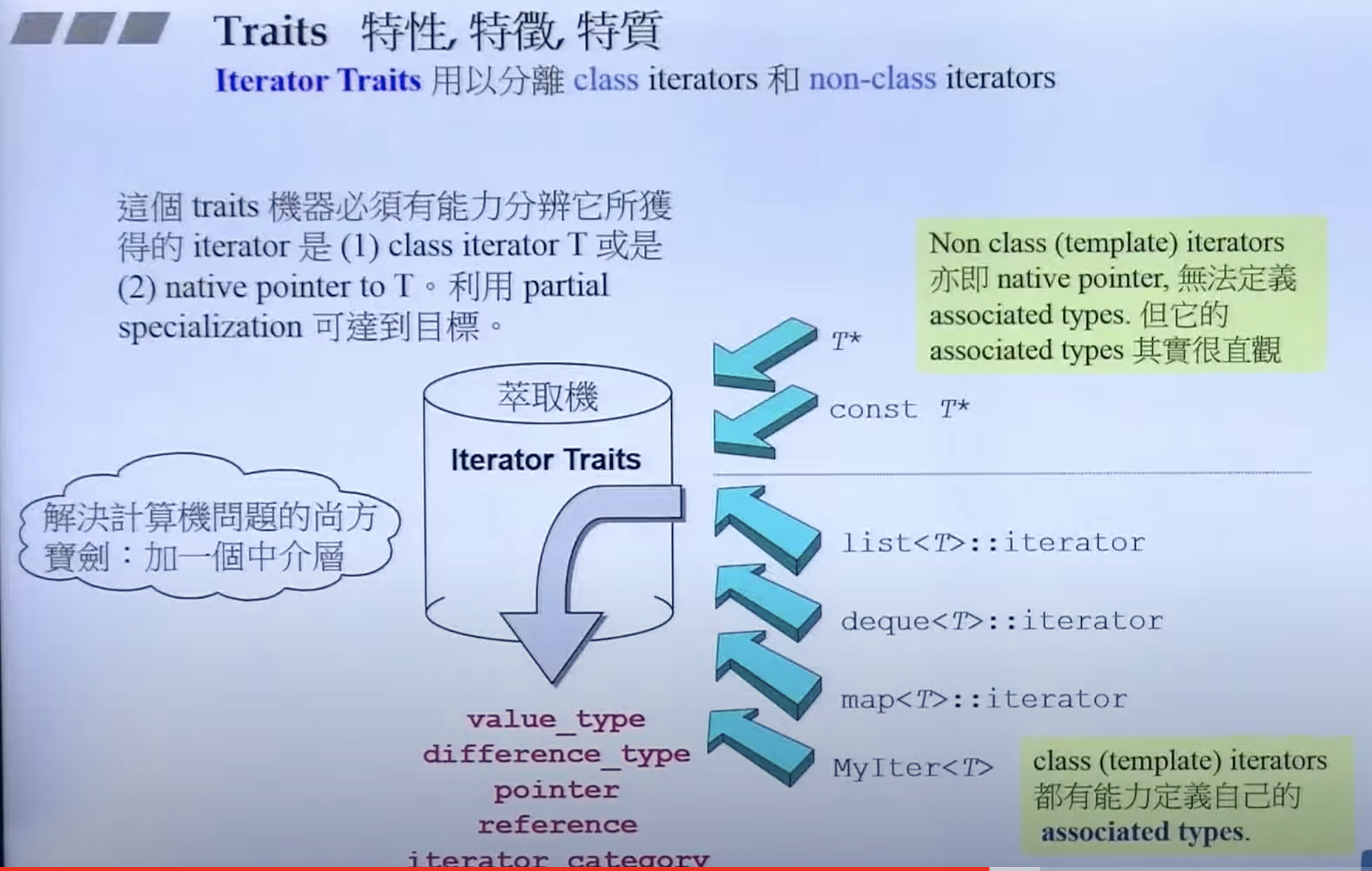
有能力把普通的指针的特性提取出来。利用偏特化可以写出萃取机:
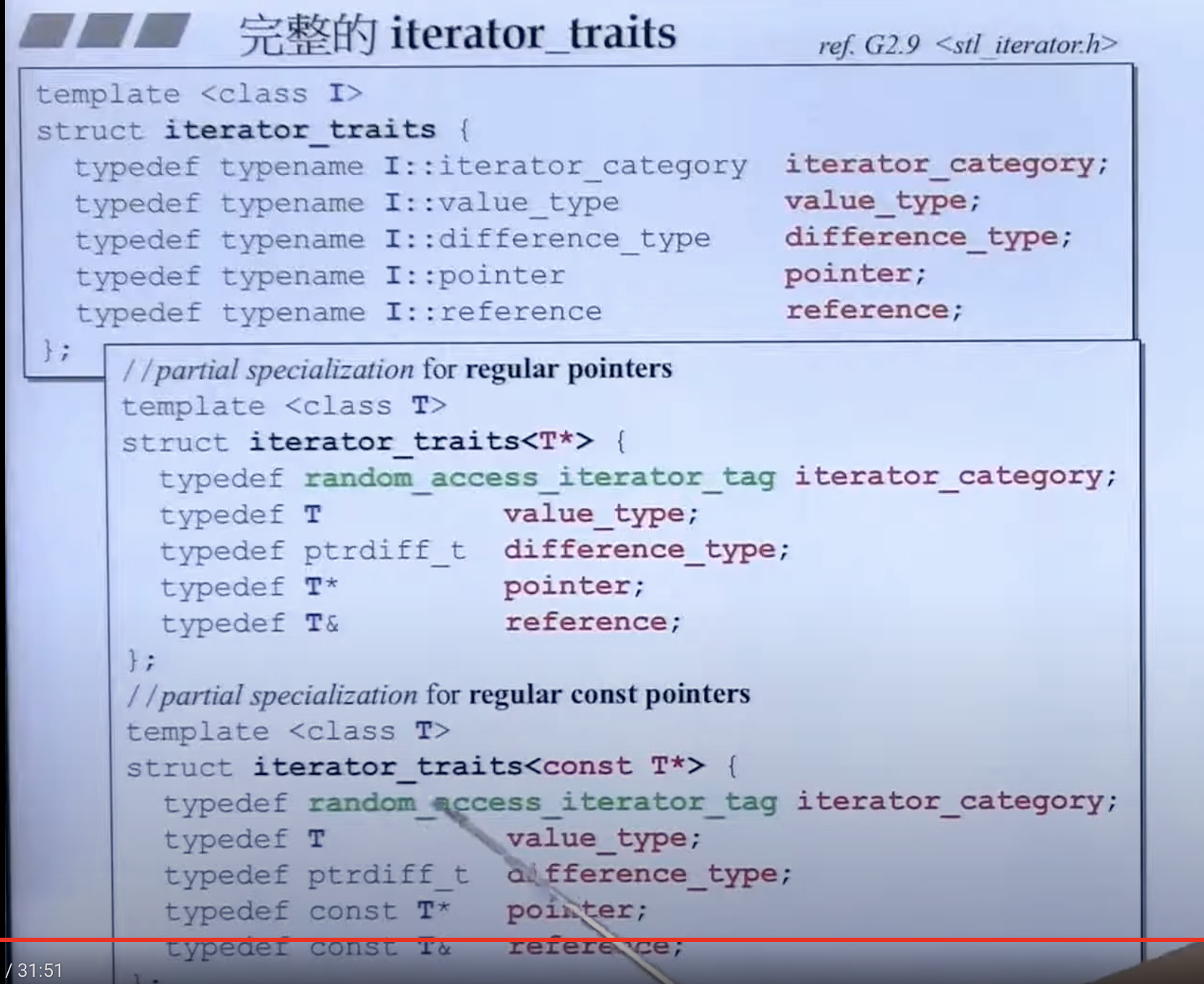
c++针对各种类型都定义有萃取机。这里加上 typename 告诉编译器这里指的是类型名,而不是模板。例:
|
|
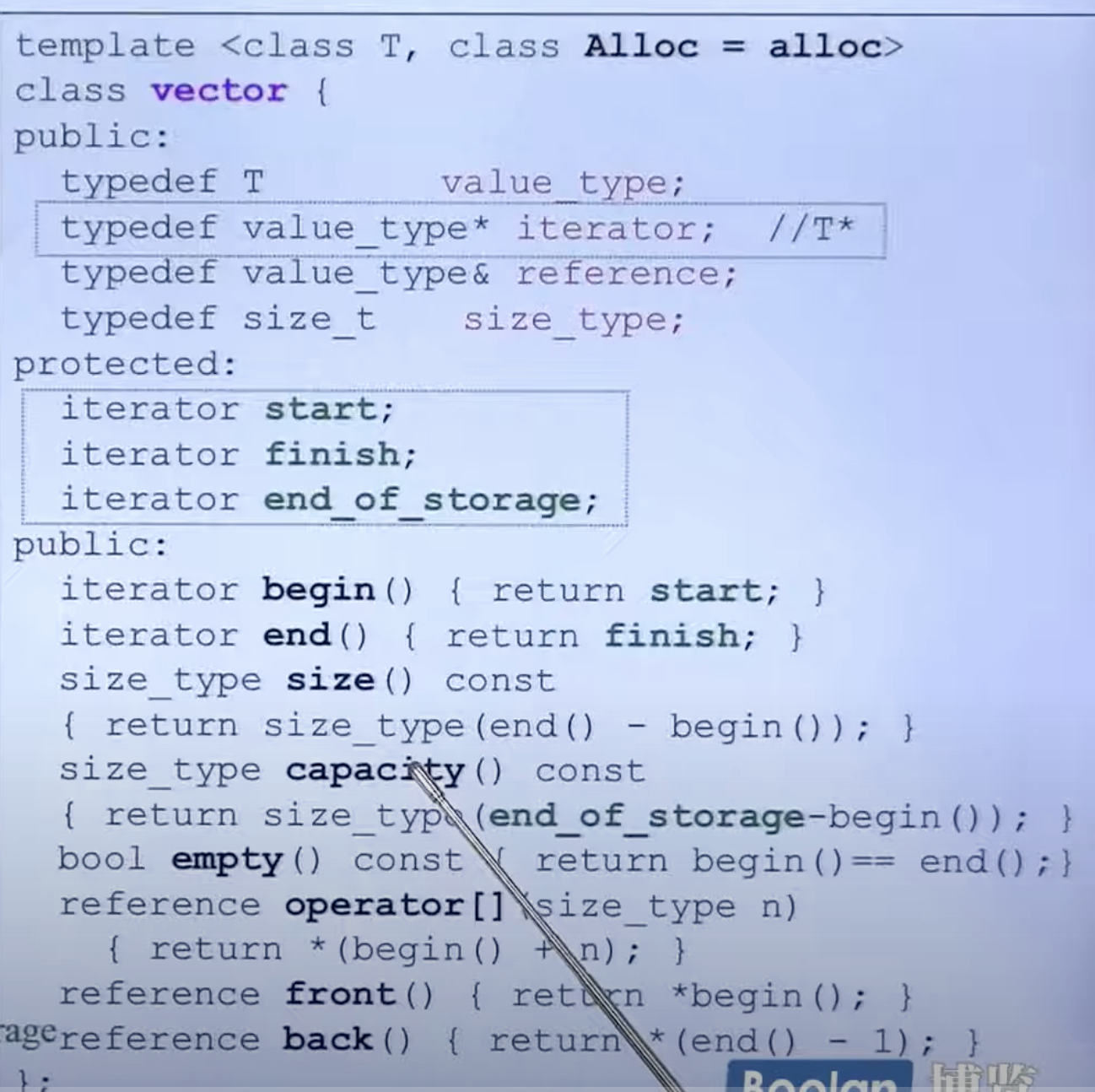
vector
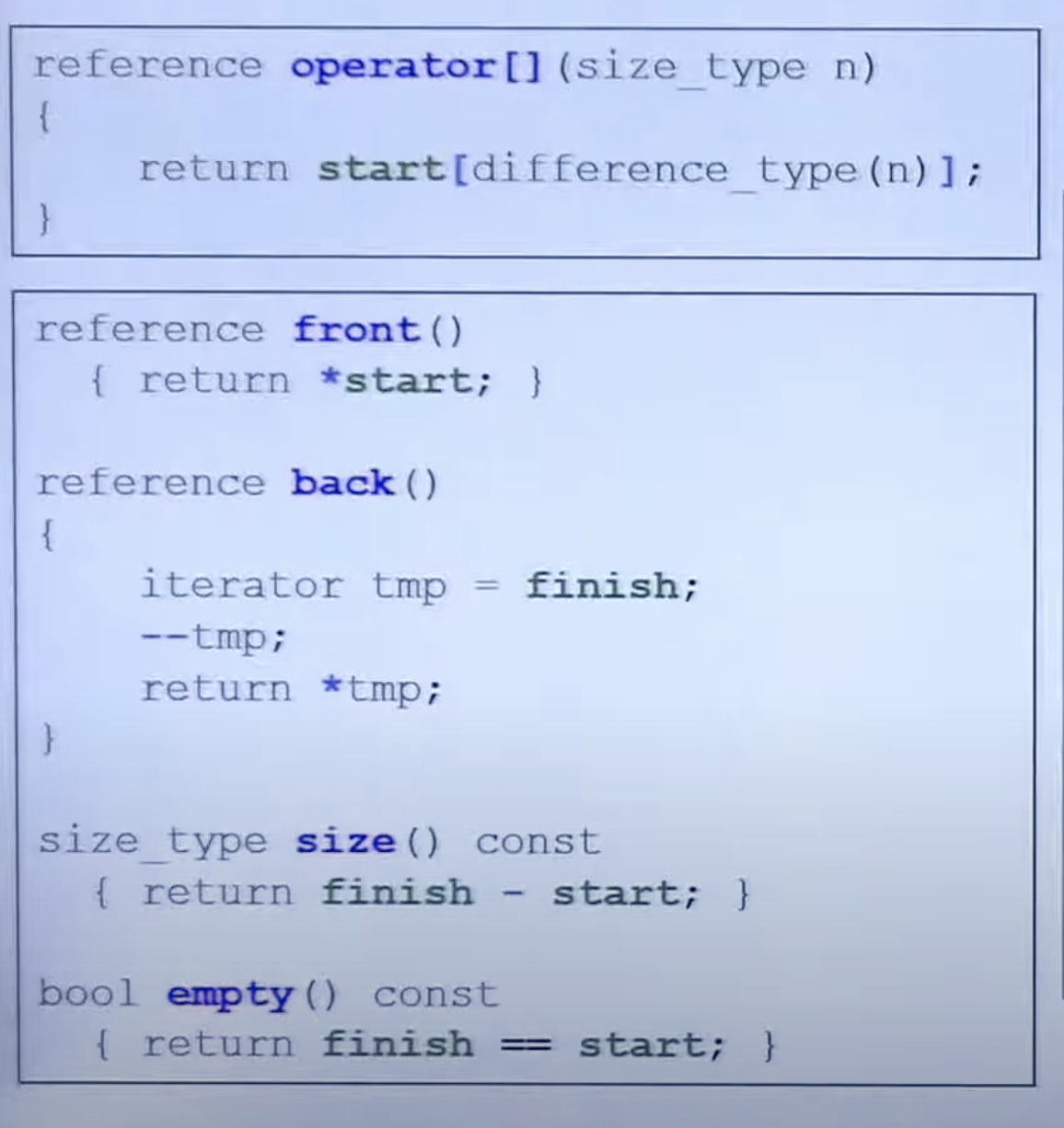
vector 包含三个迭代器(私有):start,finish,end_of_storage。
装满了之后会两倍成长。
增长的过程:
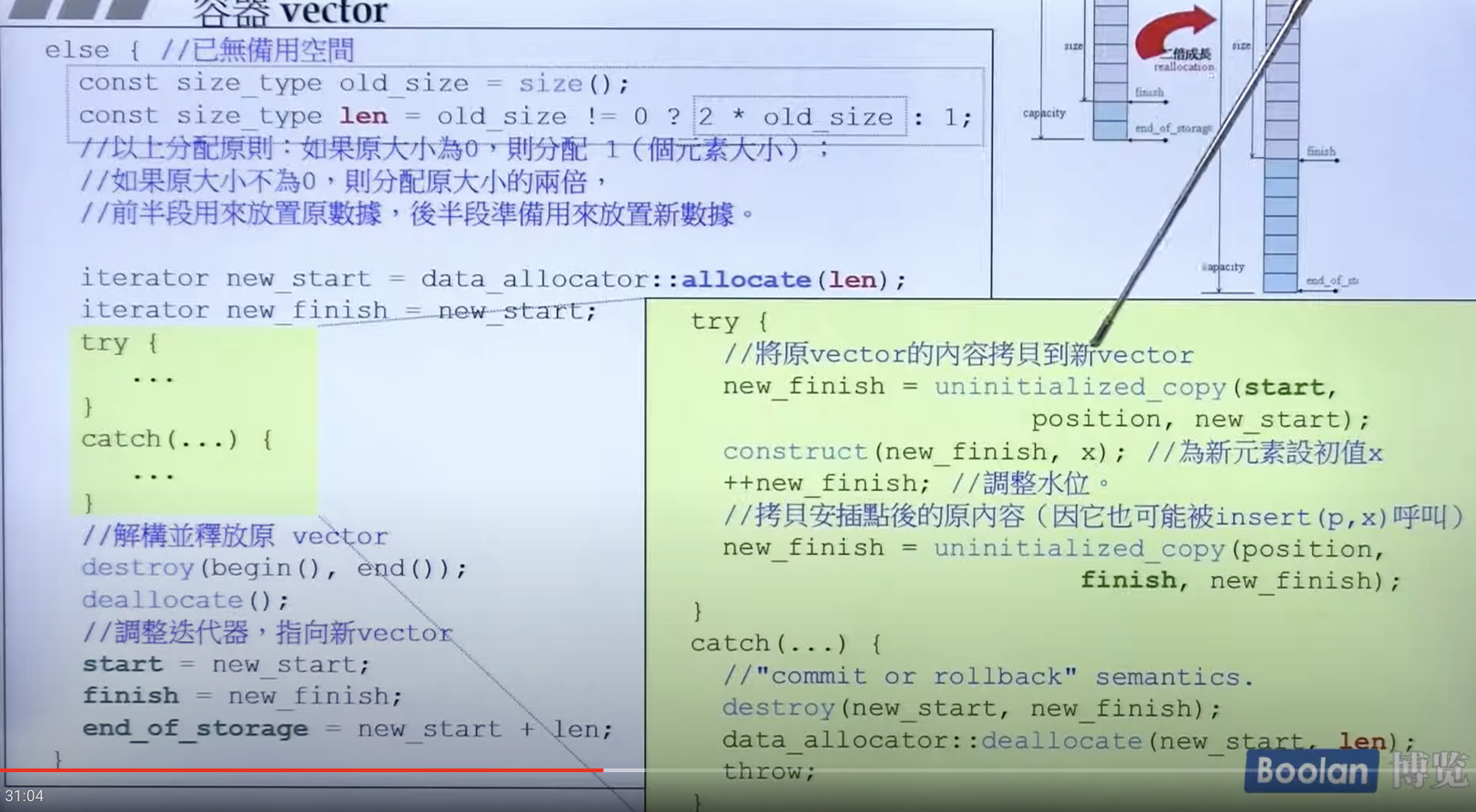
注意在 c++11 中右值引用的方法如何降低了增长的成本?
GCC4.9中的 vector:
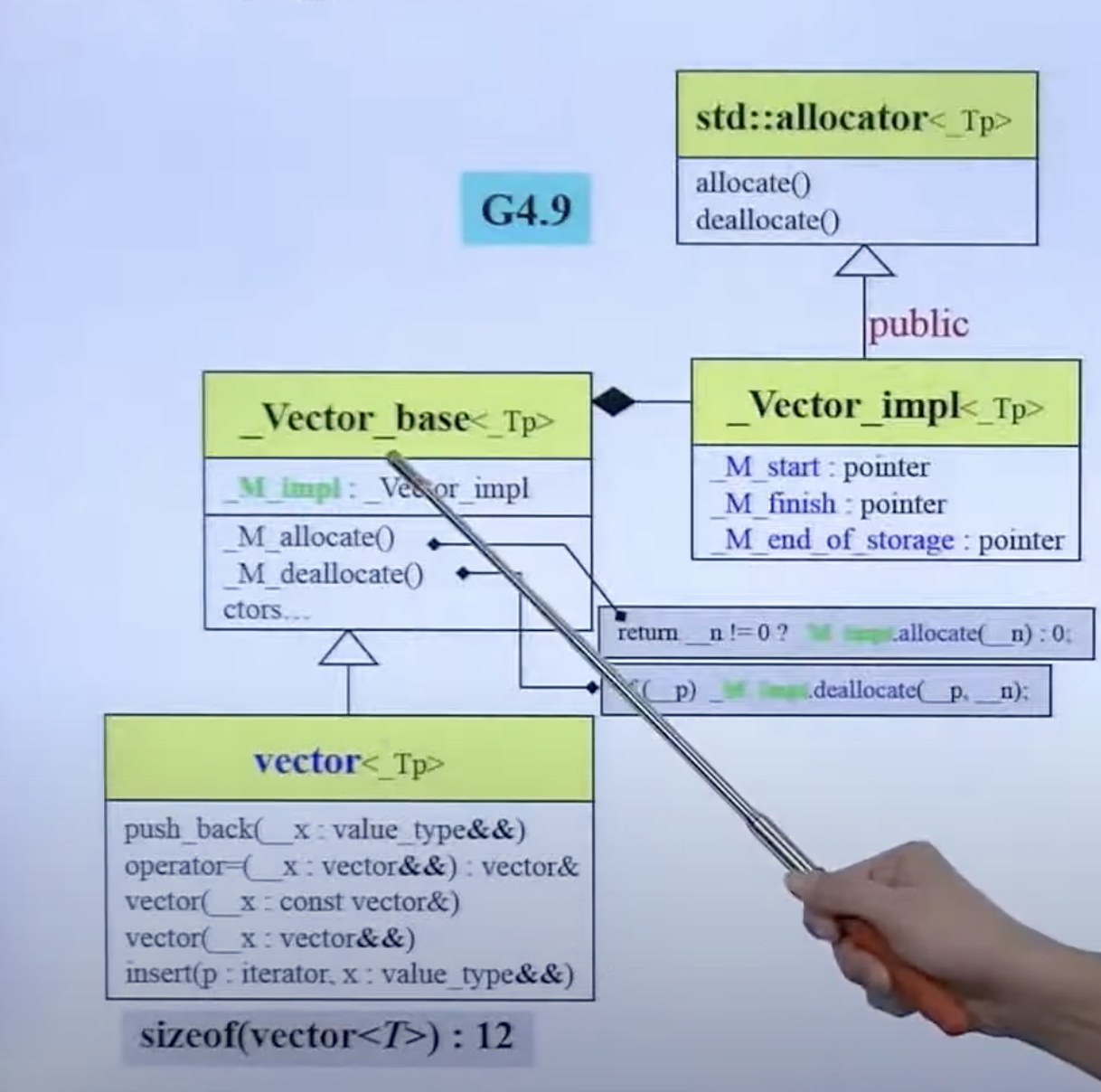
又变得复杂了。
array
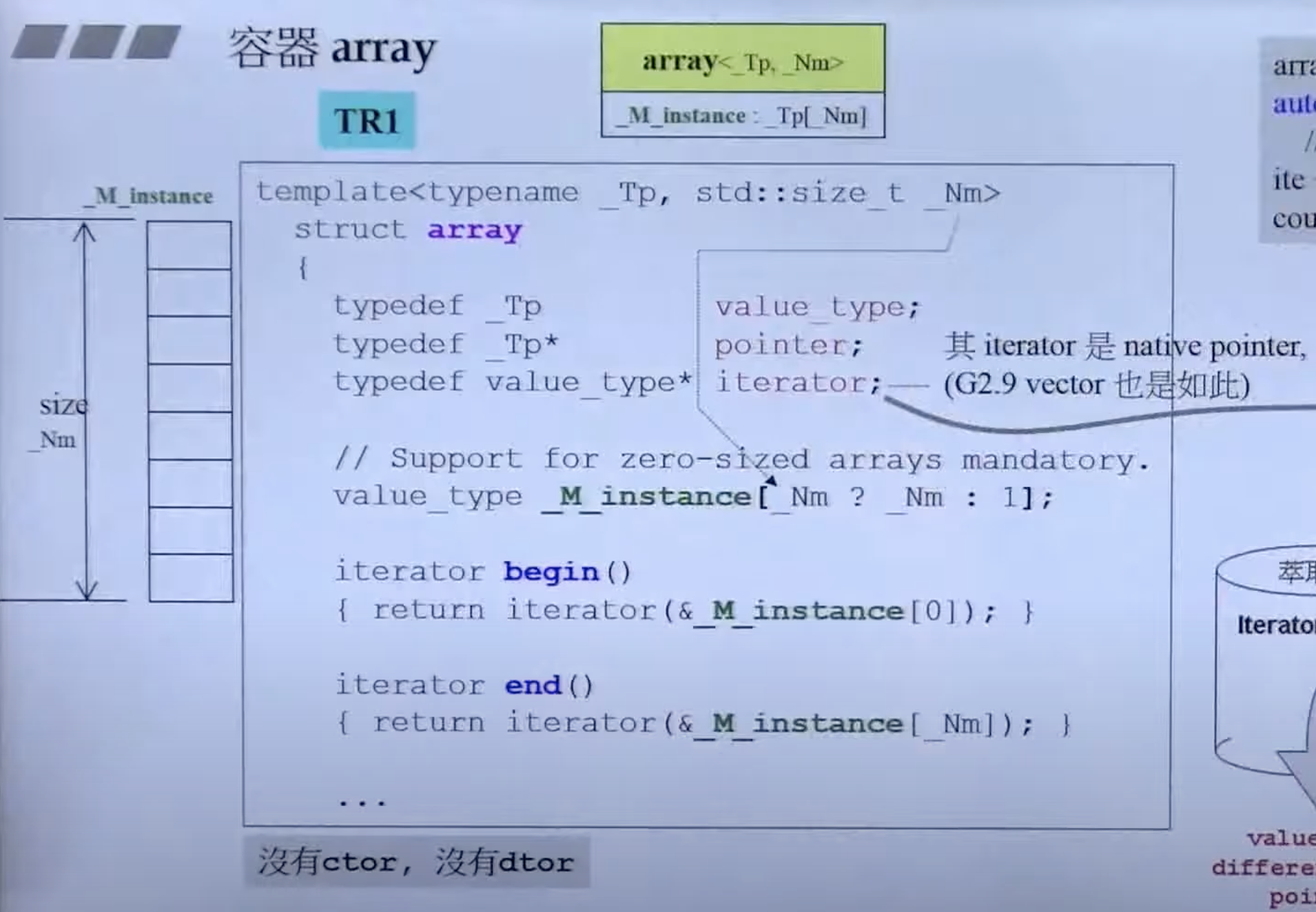
array 必须指定大小
|
|
疑问:template<typename *Tp, std::size_*t _Nm> 代表模板里面可以放参数? 是的。
array 其实只是对数组做了一层包装,加上 iterator。
疑问:为什么这里的 begin 和 end 函数要加上 noexcept?

deque,queue 和stack
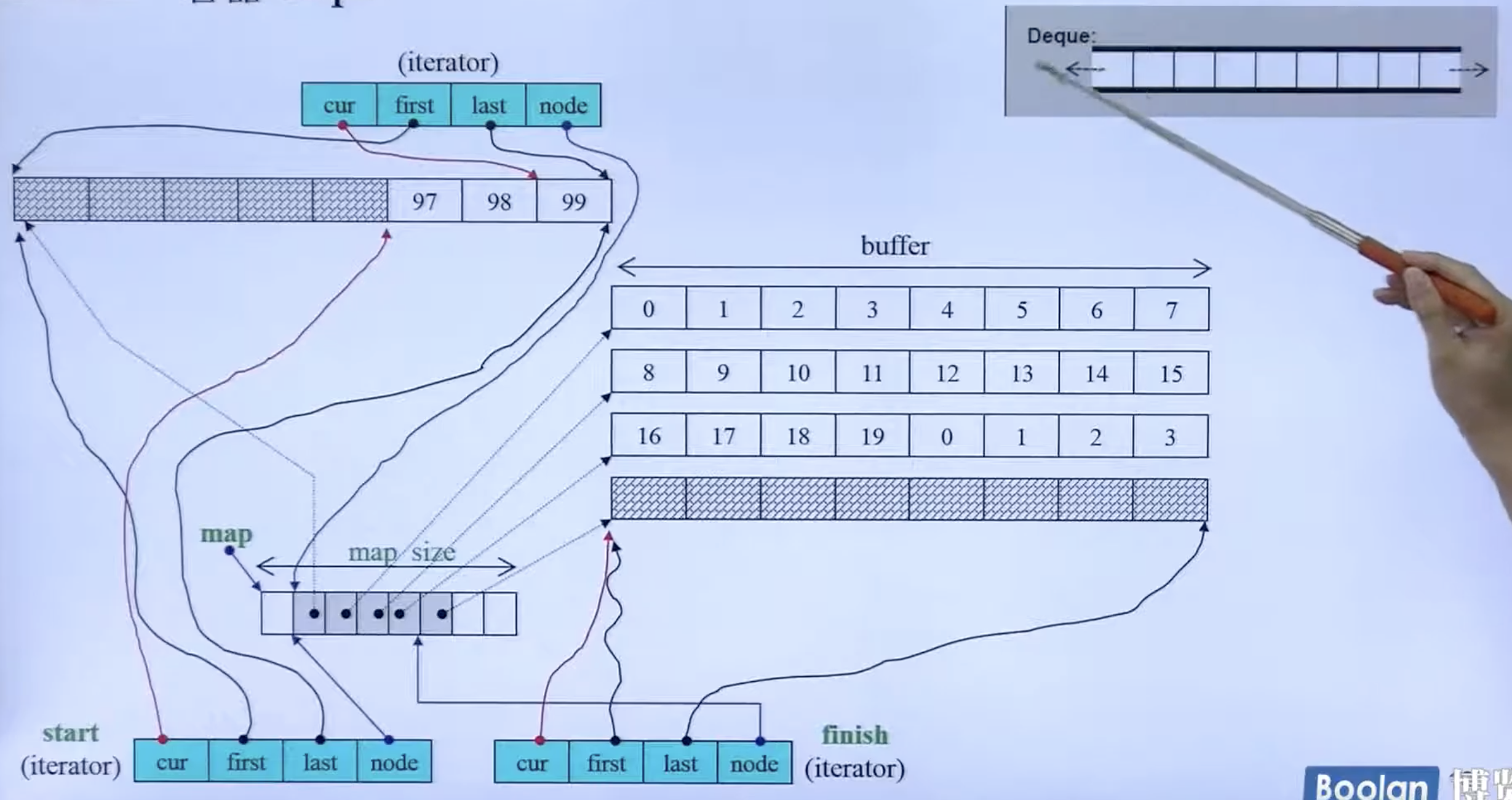
- deque 其实是分段连续,对外表现形式为连续。底层的一个 vector 中放的每个元素都是一个指针,分别指向一段连续 buffer。多段的 buffer 形成了连续的队列。当 某一段 buffer 用完,vector 添加一个指针在后端,申请一段新的 buffer。
- vector 扩张时,原有的指针会被复制到新 vector 的中央。
- deque 的迭代器是一个 class,有四个指针。其中first 指向当前缓冲区的头部,last 指向当前缓冲区的尾部,node 指向 vector。vector 这里起到了 buffer 之间的连接功能。
- 当 cur 走到了某个缓冲区的尾部,迭代器会自动回到 vector 中找到下一个缓冲区。
- start 和 finish 迭代器如图所示,一切都按照 iterator 的接口来定义。
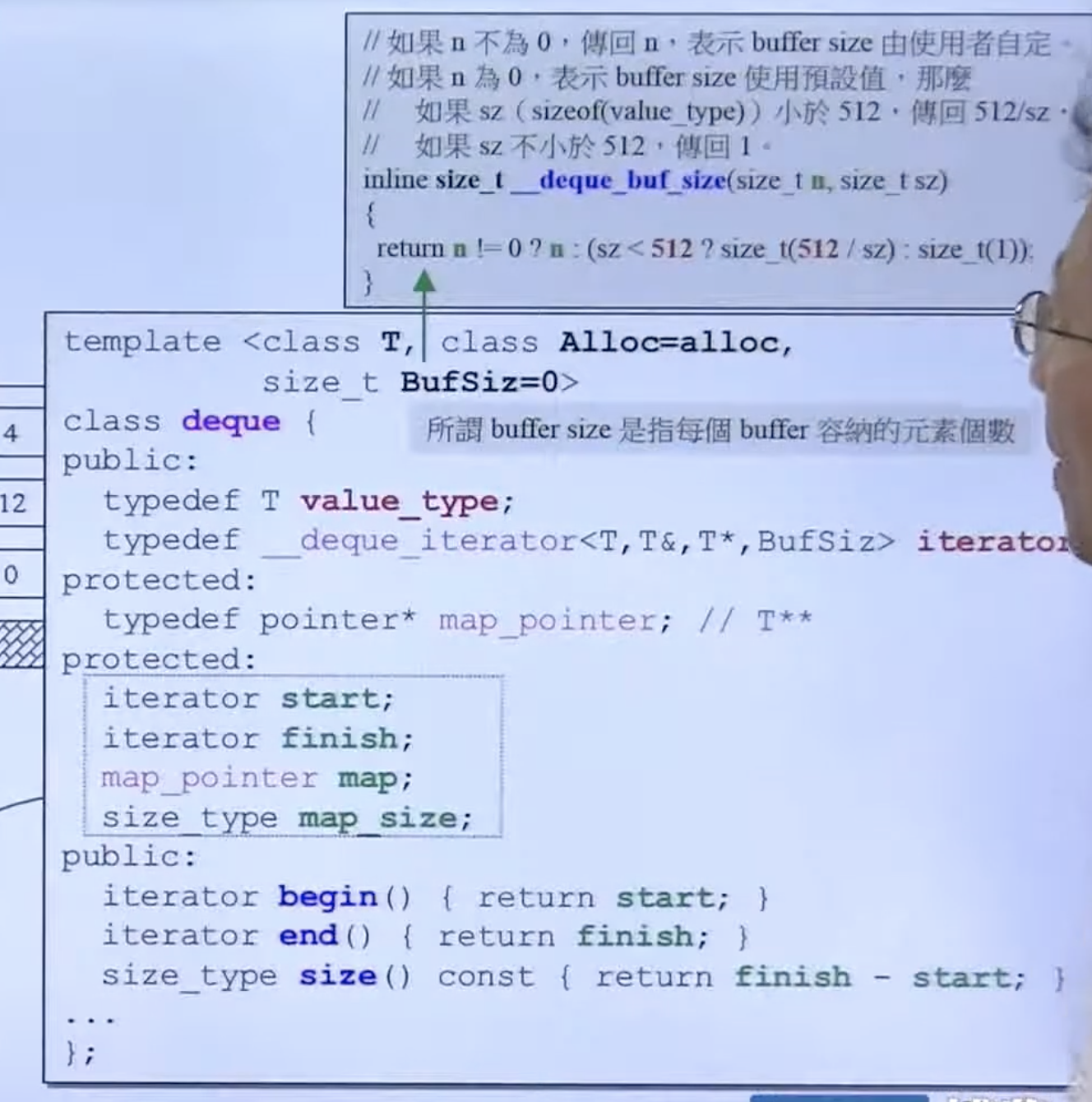
新版不再允许自定义 buffersize。
deque::insert()
注意 deque 是支持随机访问的,并不是单纯的双端队列。
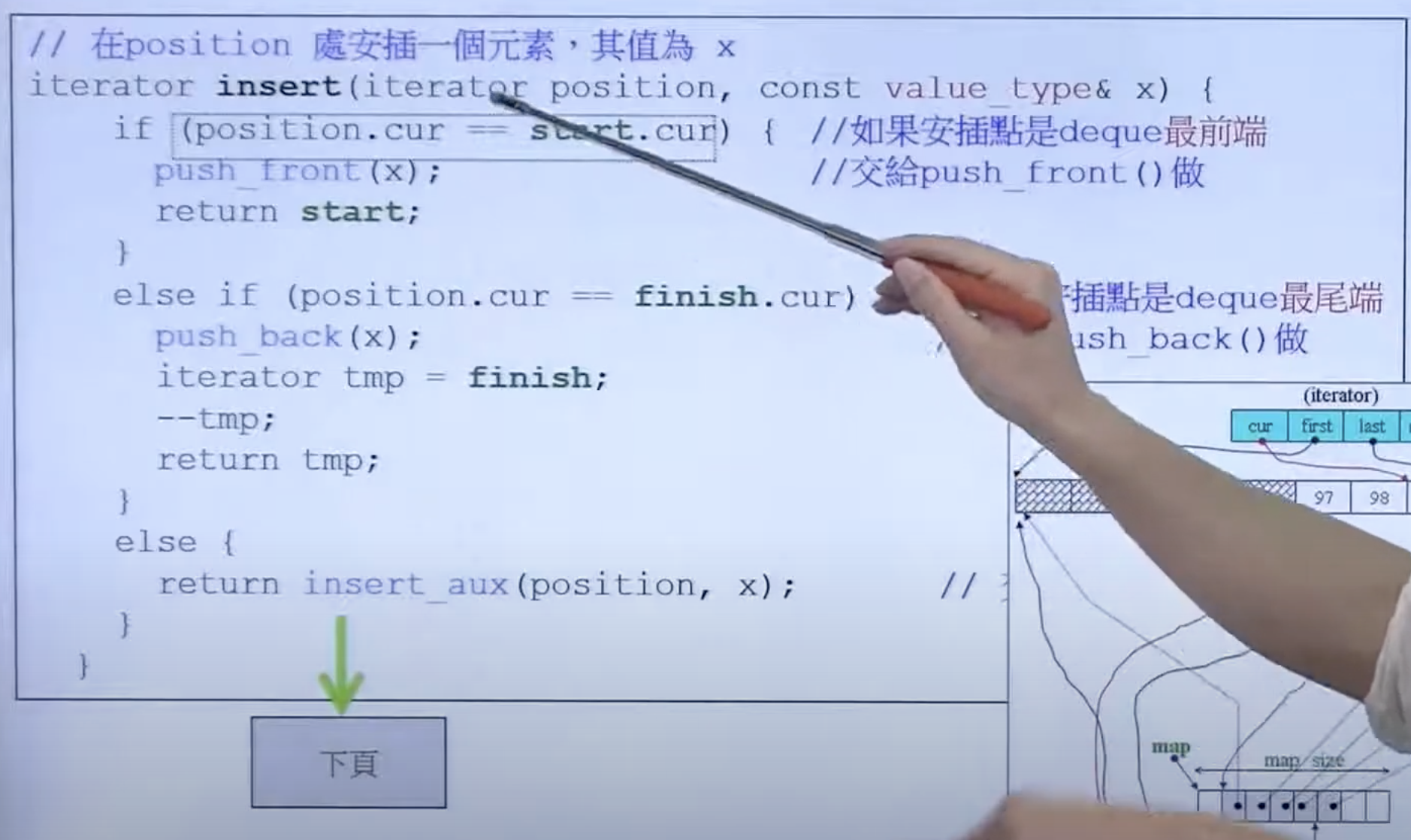
deque 需要判断元素是向前移动还是向后移动更好。
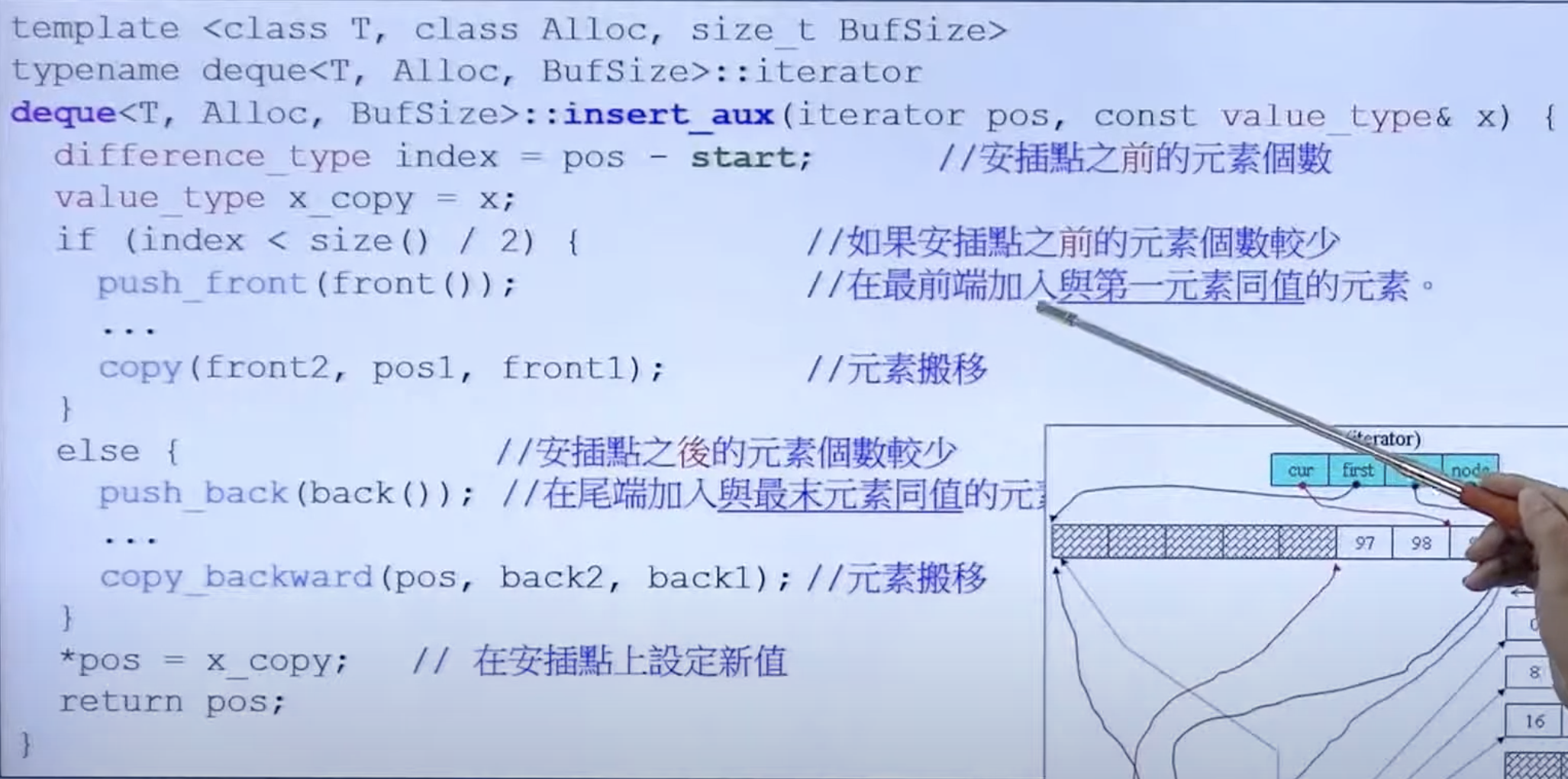
deque 中 iterator的操作符重载

简单的计算可以算出任意两个 iterator 间的距离。注意 buffersize 都是相同的。

注意一般都是用后置运算符调用前置运算符。

+可以利用+=来完成。先判断要不要跨越缓冲区,如果需要,则需计算出真正缓冲区的位置,切换到正确的缓冲区后再切换到元素的位置。
queue 和 stack
queue 和 stack都是以 deque 作为底层实现。

可以称 queue 和 stack 为 adapter。注意 queue 和 stack 都不提供iterator。一般标准容器才有 iterator。
为什么以 deque 作为底部呢?
实际上 两者可以选择 list和 deque 作为底部。
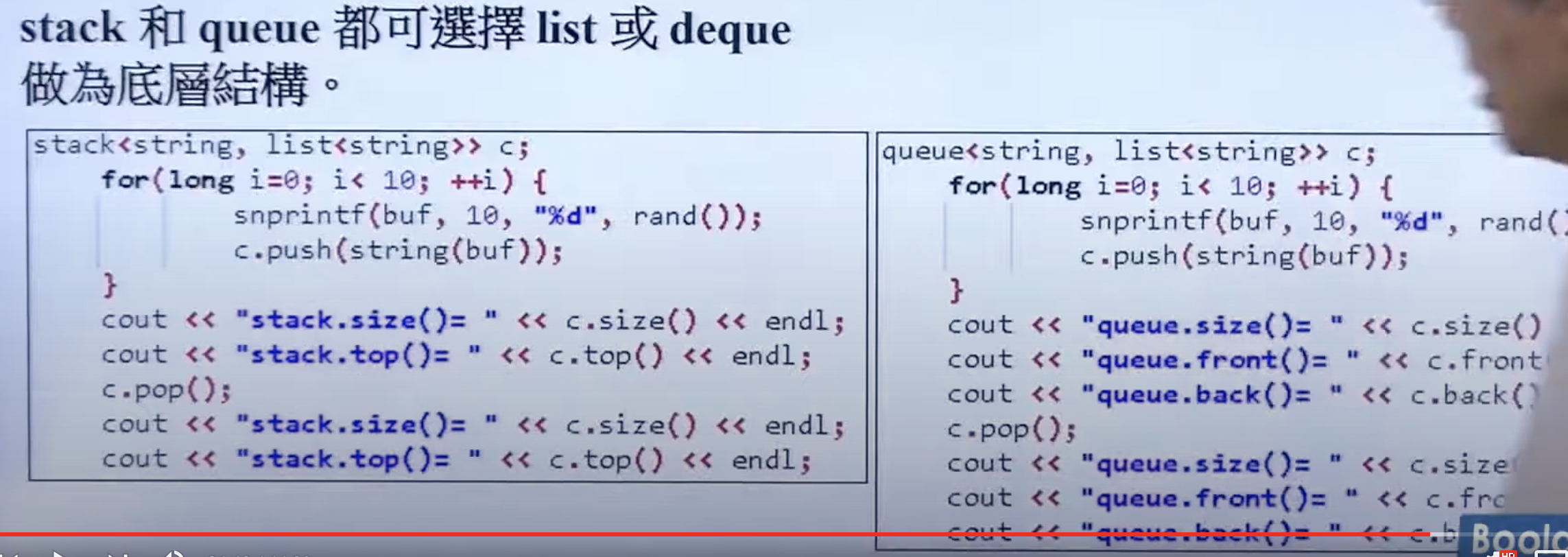
且stack 可以用 vector 做底层结构,queue 不行。因为 vector 并没有 pop_front()函数。
rb-tree
关联式容器的地步都是红黑树和 散列表 。

特性:
-
平衡二叉搜索树
-
提供遍历 iterators,能获得排序的状态。
begin为最左边的节点,end为最右边的节点,中序遍历。

map的排序是按照key来排序,而data是可以改变的。因此这里的元素值应该是开放修改的。
实现:

红黑树只有三个data:node_count, header, key_compare。
分别对应的是红黑树的节点数量,红黑树的头,key比较的方法。注意红黑树的header为空的,为了实现上的方便。
keyofvalue模板告诉红黑树如何从value中取出key。

key_compare的为functionlike object,大小为1。
|
|
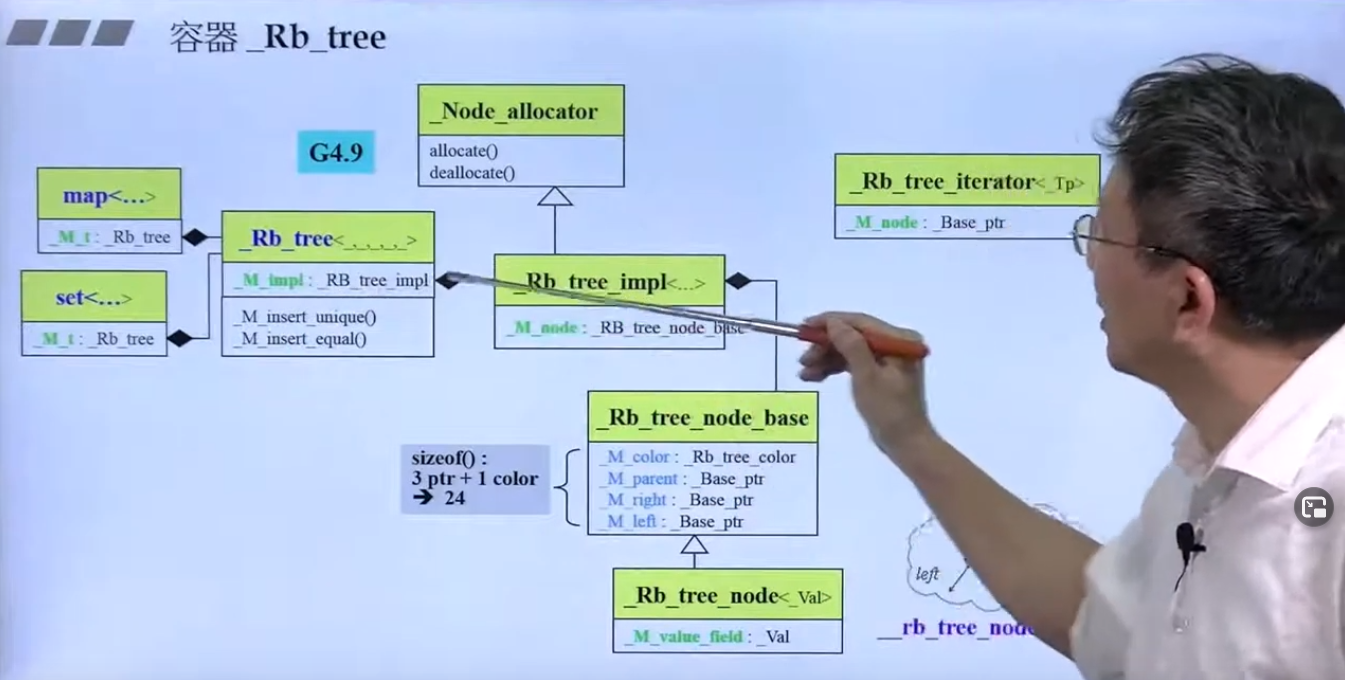
GNU4.9的版本同样变得非常复杂。实际上这是OO里面Handel的做法。
set 与 multiset
区别:元素能否重复。都是以红黑树为底层,元素会自动按照key排序。而对于set来说,key和value是同一样东西。
提供遍历和iterators。无法通过迭代器来赋值。

这里GNU的identity指的是key即value。而在VC6下为_Kfn。
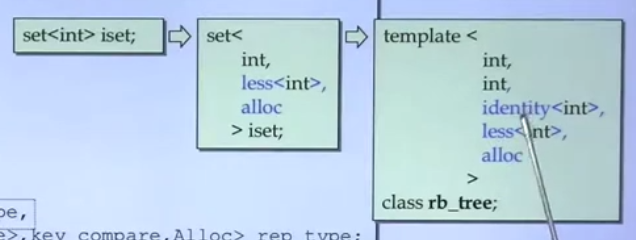
当取set的iterator时,取到的其实是rb_tree的const_iterator。

所以set也是adapter。 set和multiset的区别仅仅是insert函数调用的不同。
map 和 multimap
map与set区别在于map的daata与key并不相同。

map应该做到无法改变key,但是可以改变data。
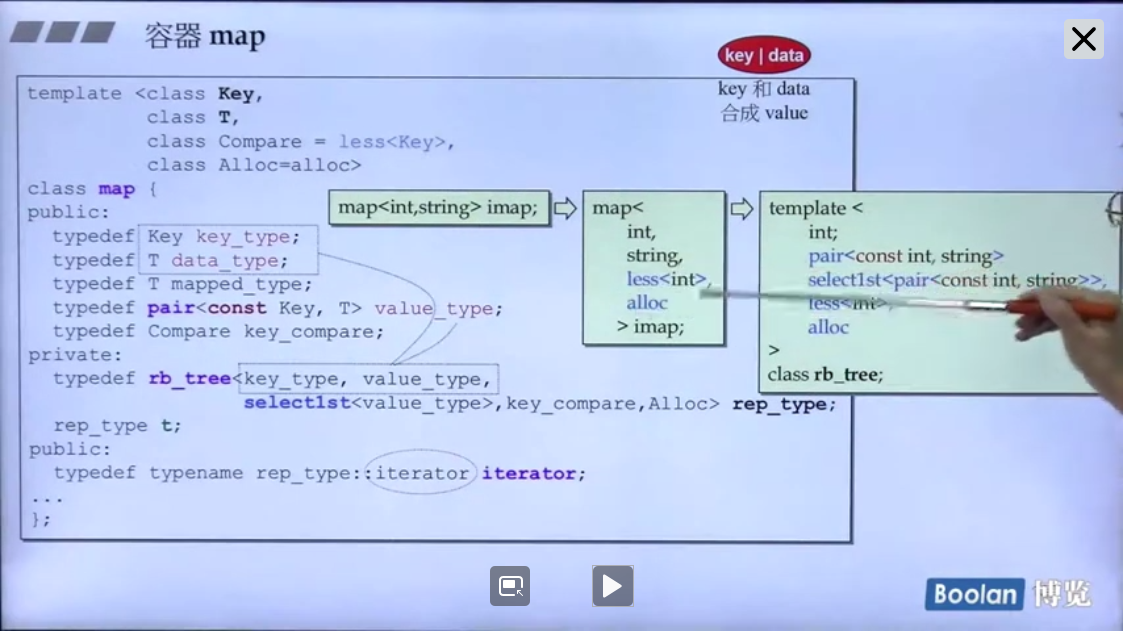
留意这里的Key被const所修饰,因此不能被修改。这里的keyofvalue则是selectfirst。这也是显而易见的。
而对于multimap而言,这样的操作是非法的。
|
|
对于map的[]重载,当key不存在时,会使用默认值创建这个元素。

除此之外,安插key的位置是由lower_bound函数实现的。
hashtable
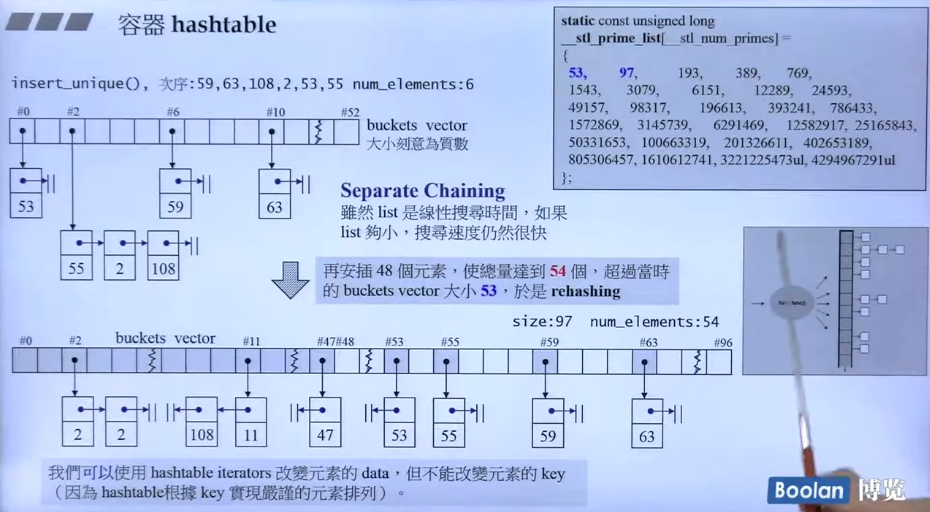
有一个约定俗成的经验规则:当元素个数达到数组长度,rehashing。数组的长度变为两倍。

设计特点:
- Hashfunction 可以建立一个元素到一个数值的映射。
- ExtractKey是一个可以从传入元素的得到key的一个function。
- EqualKey 一个比较key是否相等的函数。
- node就是平常的单向链表。
- iterator 的设计就是两个指针。
hashtable的使用:
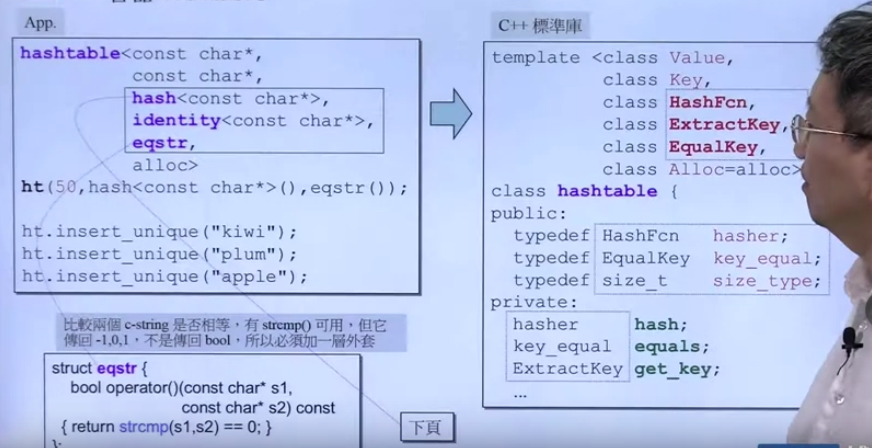
unordered類的容器底層都是紅黑樹。
算法 Algorithm
从语言层面来说,只有算法是函数模板,其他都是类模板。

算法借iterator来获取机制来执行。
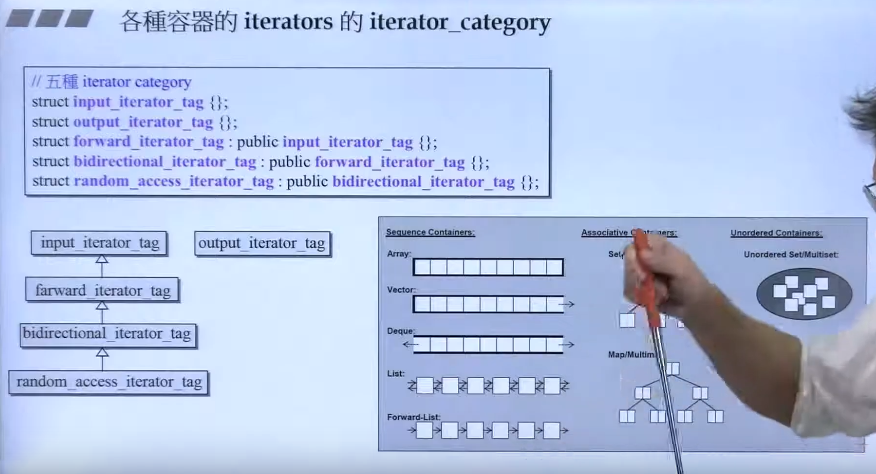
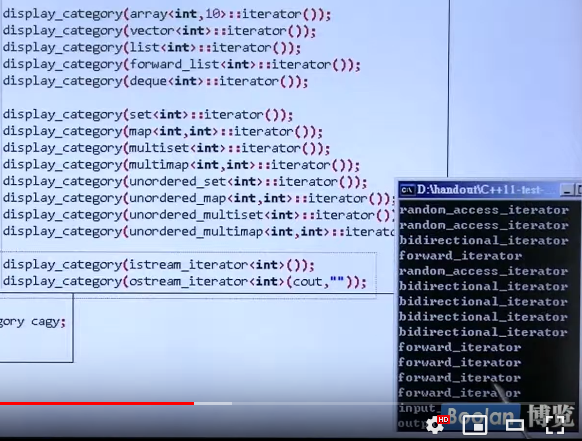
各个容器的iterator tag:
iterator_category 对算法的影响

可以看到distance()函数针对不同的迭代器做了不一样的特化。
iterators的继承关系,会使得子类的继承迭代器调用到父类的算法。
copy()对迭代器的优化:
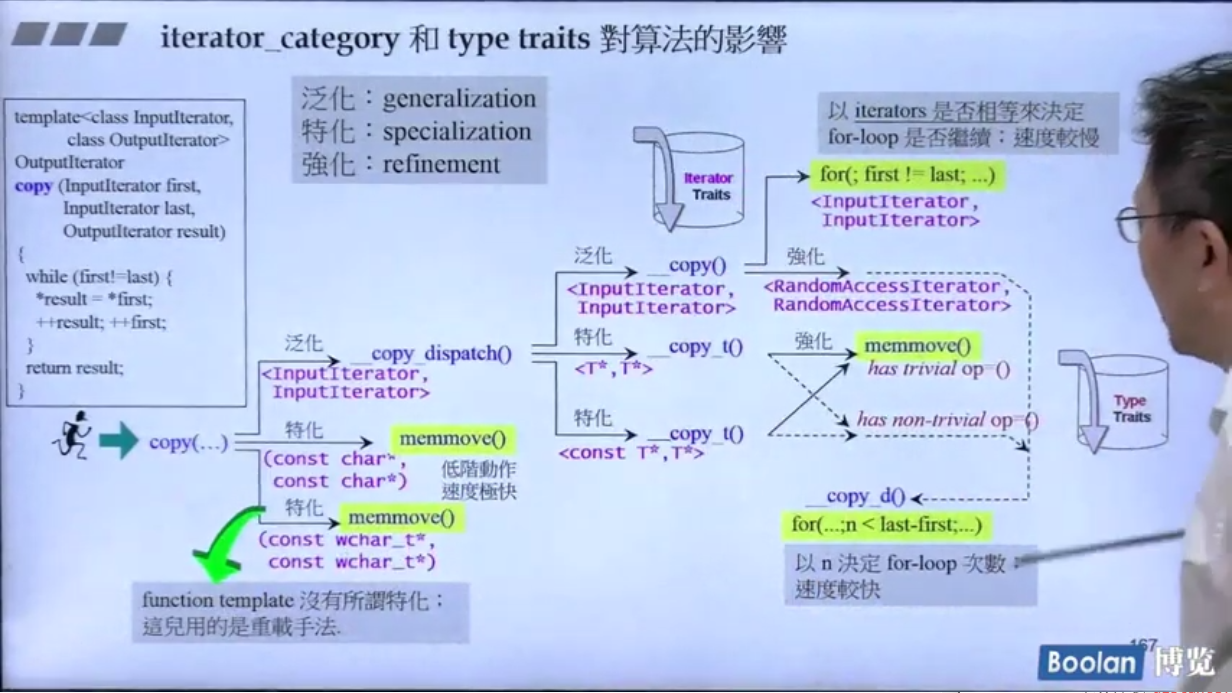
这里的type萃取机回答这个type是否具有拷贝赋值特性。默认的构造函数是不重要的(trivial)。
注意算法中的函数参数仅仅只是模板,不一定一定要指定的iterator。仅仅是暗示需要什么迭代器。
算法实现剖析
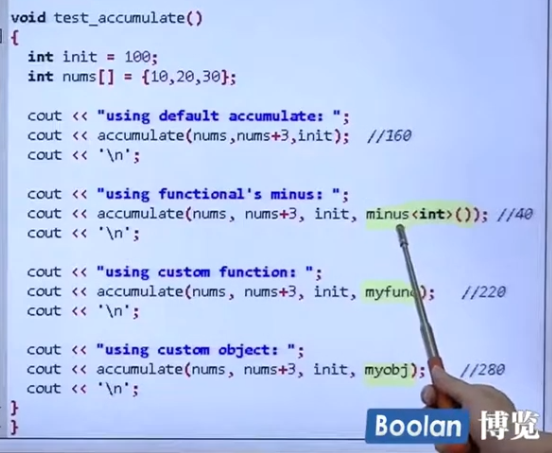
accumulate 累计算法

注意C中的数组也要遵循前闭后开区间规则。
for_each:

replace:

count:

关联式容器自带count函数。
关于这里返回值为什么要加typename:
C++ typename 用法 - youxin - 博客园
find 也类似于count。
sort:
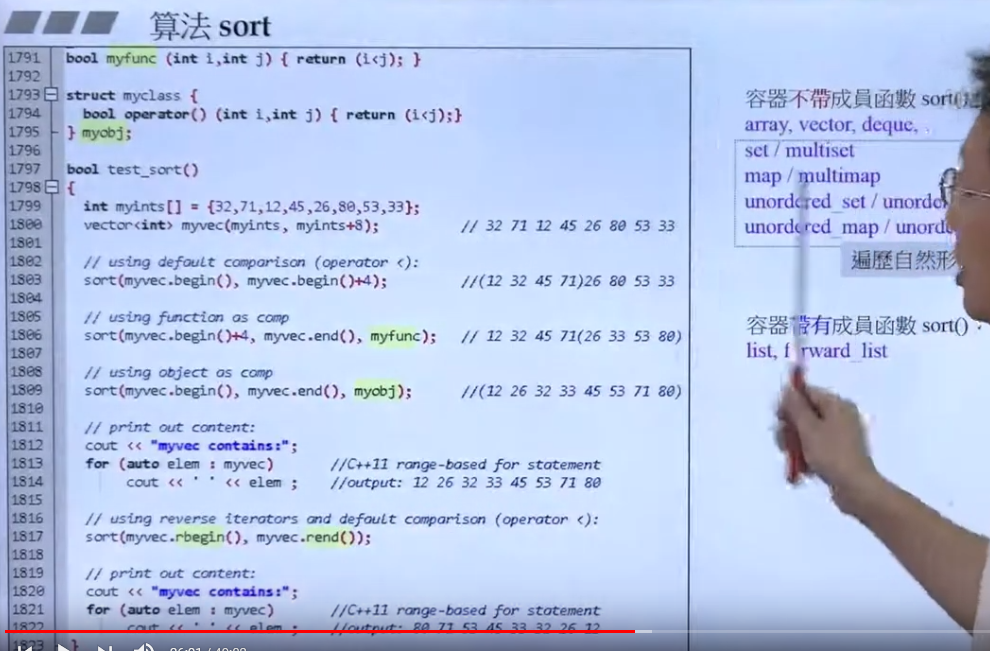
这里myvec.rbegin() myvec.rend() 是反向迭代器。还有cbegin()和cend()为常量迭代器。
binary_search:

lower_bound()不改变排序的情况下能插入target的最低点。upper_bound()不改变排序能插入target的最高点。
二分查找借助了lower_bound() 函数。注意这里返回的只是bool。
仿函数 functors
STL中最简单的部件。最容易自己写的部分。皆是function like class。
二元:
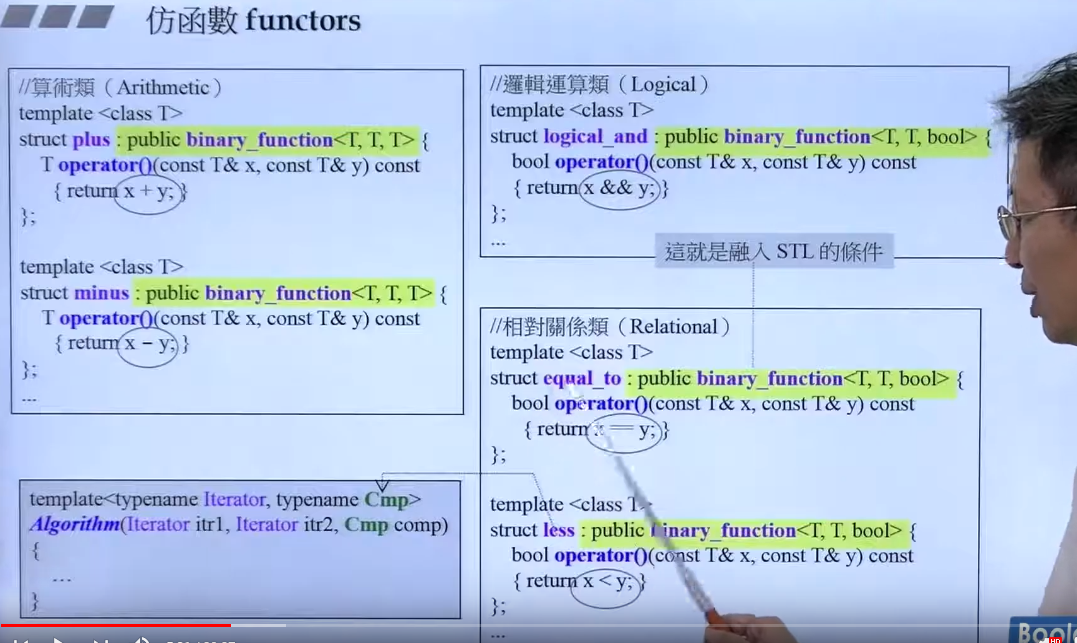
二元函数继承binary_function<T1, T2, Result> 后即可使用。
一元:

注意这些函数非标准库一部分。类似的,继承自unary_function<Arg,Result> 。不继承的话也可以运行,但是不继承会带来问题。
functors的可适配条件

有了三个typedef,才能回答Function Adapter的问题:

适配器 Adapter
是设计模式之中的一个。存在很多Adapter。
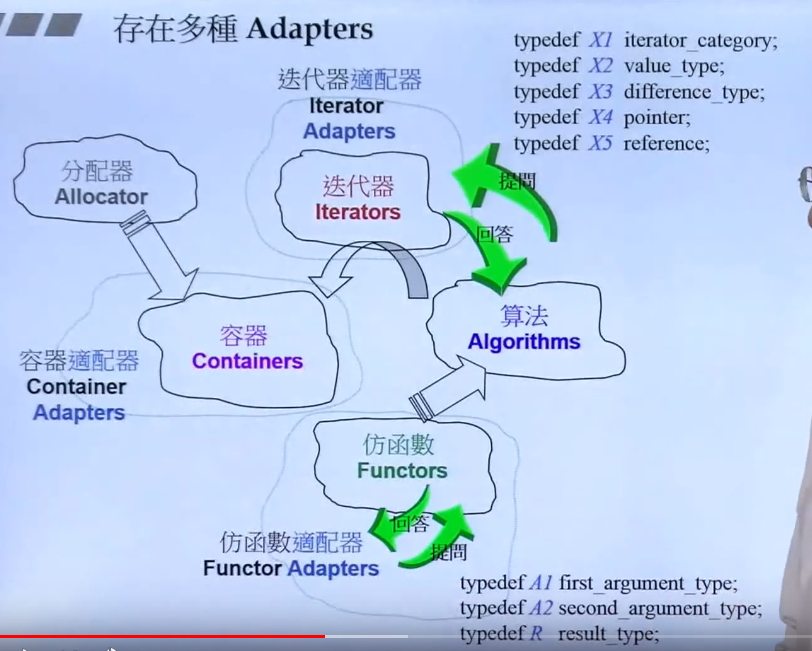
有容器适配器、迭代器适配器和仿函数适配器,都是使用组合的方式而非继承。
如stack和queue都是deque的容器适配器,它们内含一个deque。
函数适配器
bind2nd(c++11中被弃用)

没有not1函数时,这里计算有多少个元素小于40.
bind2nd起到了把第二个参数绑定为40的作用。
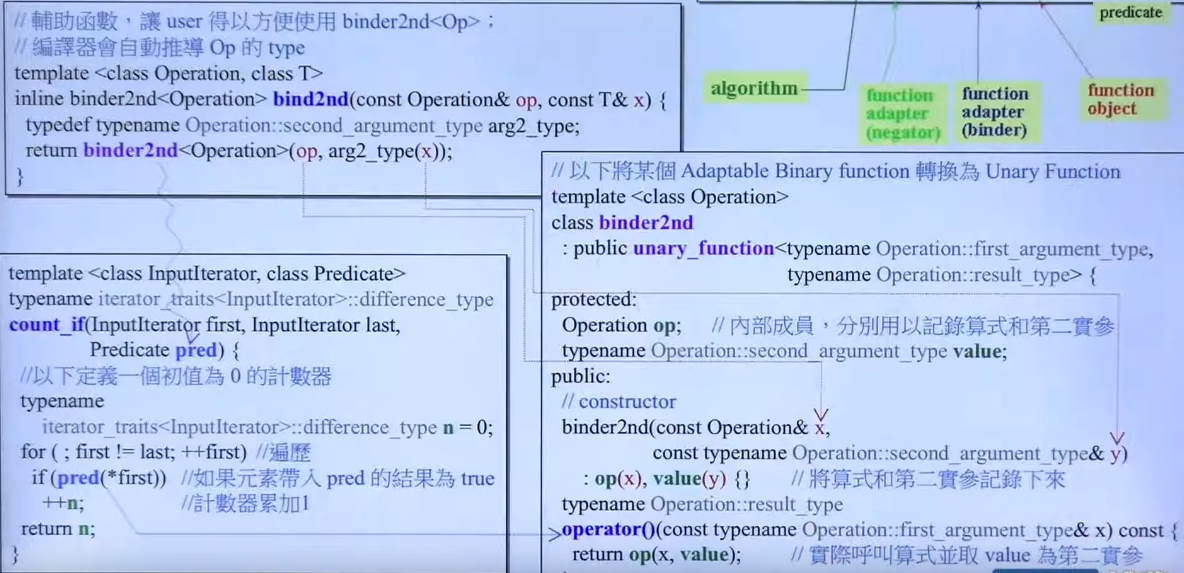
实际上创建了一个对象,这个对象的数据成员value记录第二个参数的值,op记录函数对象,()重载时直接调用把value传进去用作第二个参数。
注意这里bind2nd函数(左上角)返回的是一个临时对象,而非函数调用的结果。
辅助函数起到了自动推导Operation的作用:
|
|
typedef 类型 arg2_type是为了确保第二个参数不错误。如输入double时,会直接转换为int。这里其实作为function的可适配条件(adaptable)。
而本身bind2nd继承自unary_function,作为一元函数。
新型的适配器bind:

在新版本中被bind淘汰。bind的实现机制比较复杂。
not1
not1函数在这里是否定的意思。

虽然只是一个取否操作,但是为了adaptable的性质,需要做出一些工作。
bind 新型适配器

使用方法:
|
|
另外bind<int>(args...)代表返回类型为int。
绑定member function:
|
|
绑定member data也类似。

迭代器适配器
reverse iterator
rbegin() 和 rend()
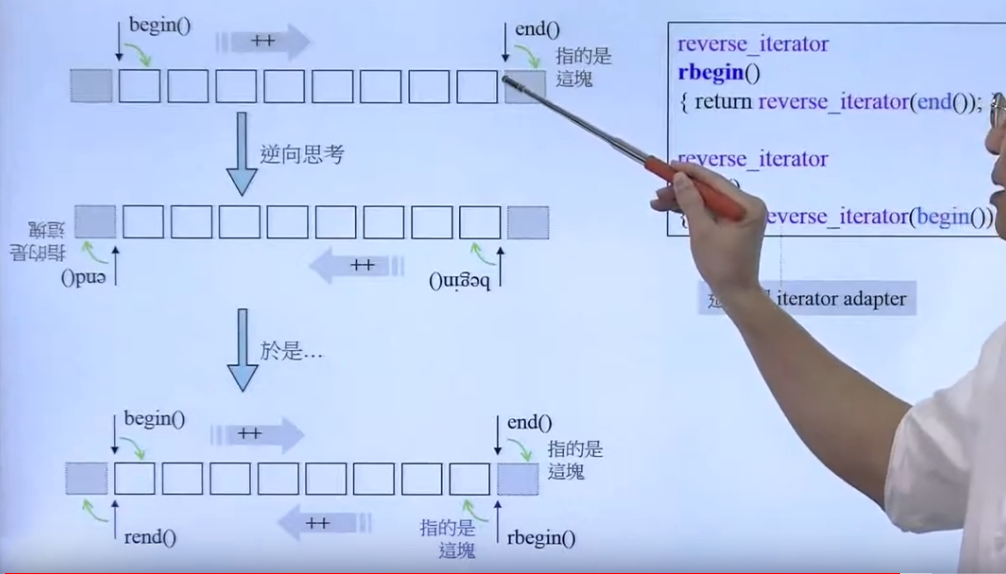
可以看做从尾往头的一个迭代器。

操作符重载也要做相应的变化。
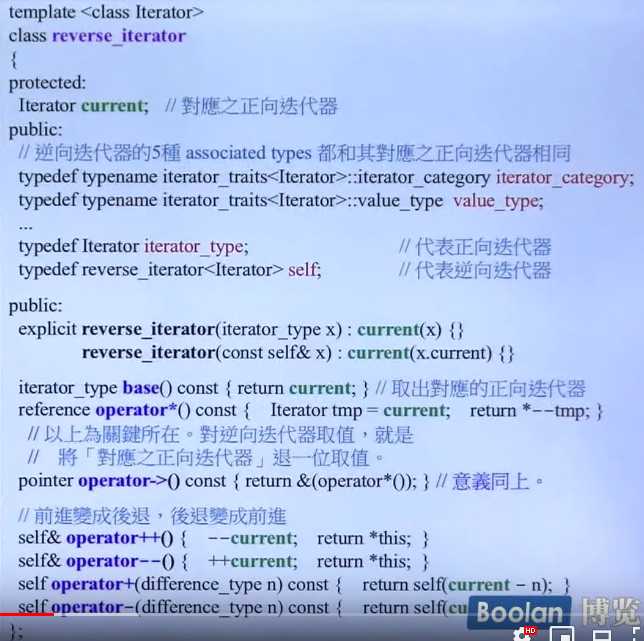
留意对逆向取值其实就是对正向退一位取值。
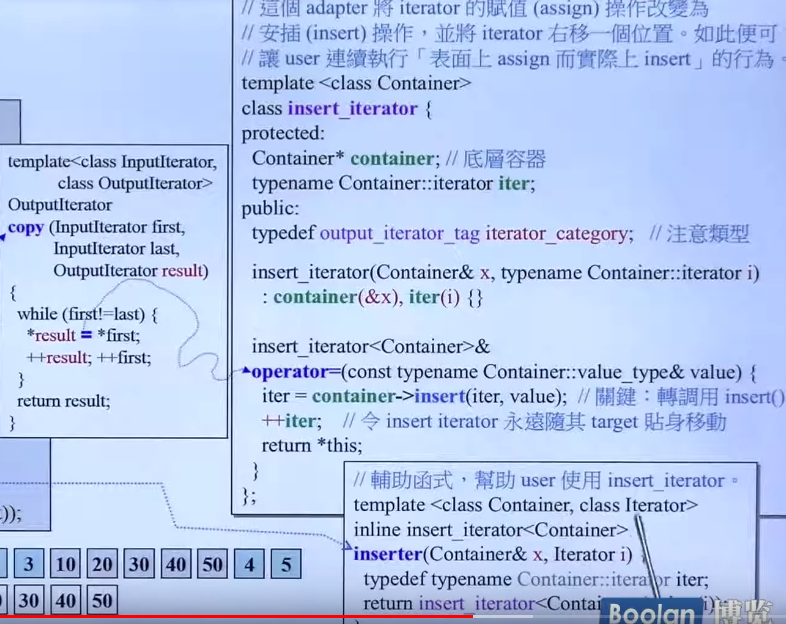
inserter
insert会自己创建空间,插入到容器中。
|
|
实现的方式为把=操作符重载:
未知分类的iterator
ostream_iterator

把元素copy到ostream这个容器里面,相当于直接输出。这里的逗号作为分隔符。同样是使用操作符重载来实现。

istream_iterator
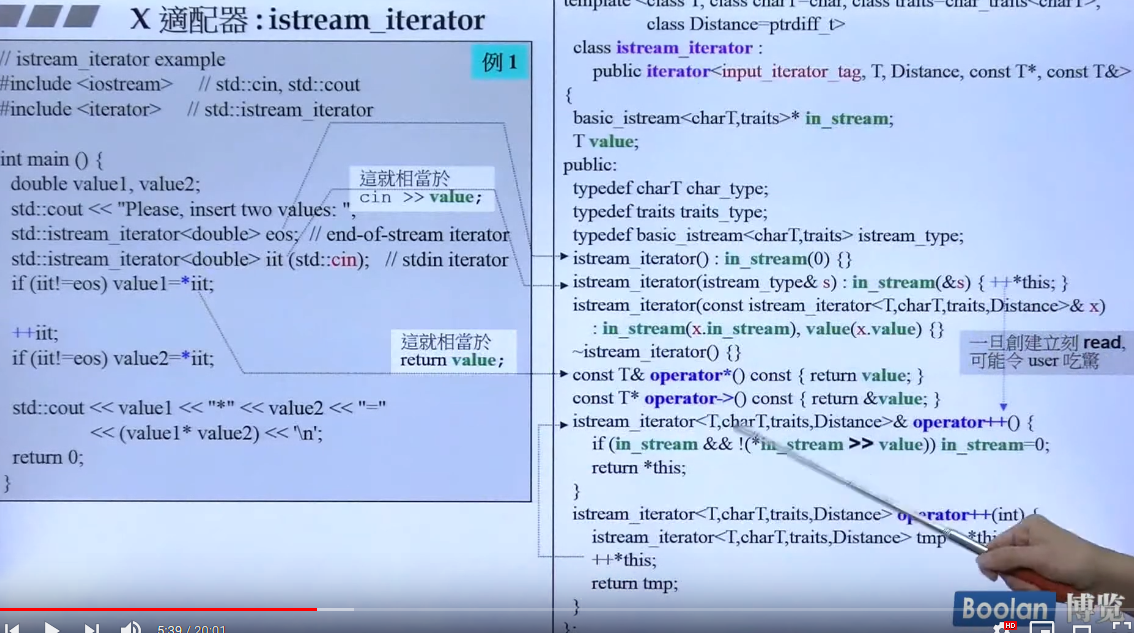
与ostream_iterator雷同,注意的是构造时就会开始读入参数。

一切设计都符合逻辑。
STL之外
万用的Hash Function
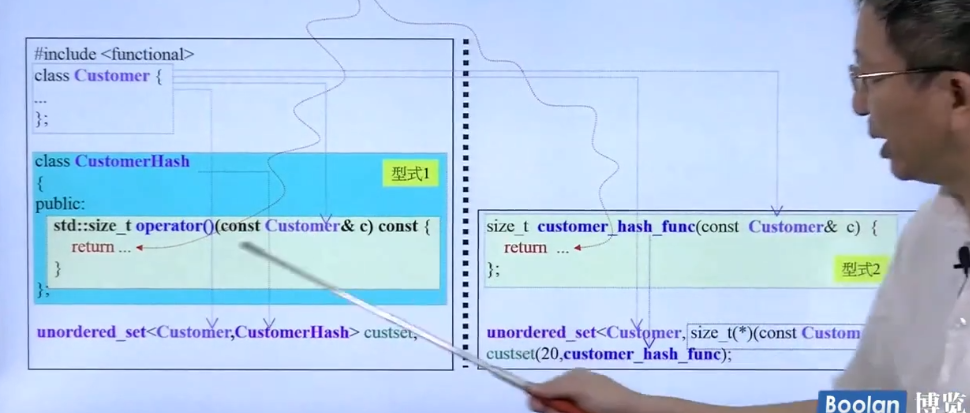
可以设计为类或者单纯的函数。最先想到的是直接把数据成员的hash值加起来:

但是碰撞会非常多。TR1:

使用variadic templates,结合seed和combine函数。
或者以偏特化的形式自己扩充STL:

tuple

实际上是一个镶嵌自己的类,以组合的形式保留数据。
type traits
https://zh.cppreference.com/w/cpp/header/type_traits
回答对于某个类型而言,构造函数等等是否重要。
C++11中添加了更多的回答,且自动完成。

是否为多态:
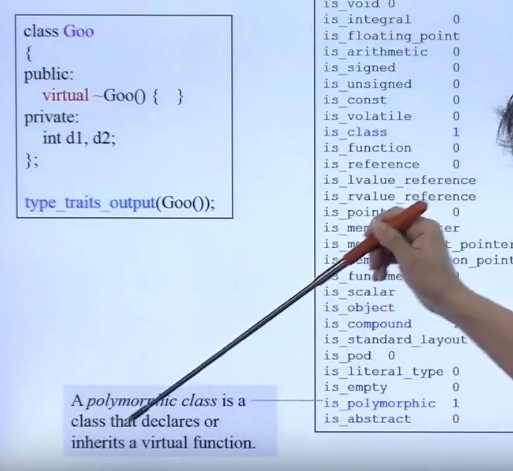
实现is_void:
利用特化去掉const和volatile,最后特化到void,如果是void就返回true。
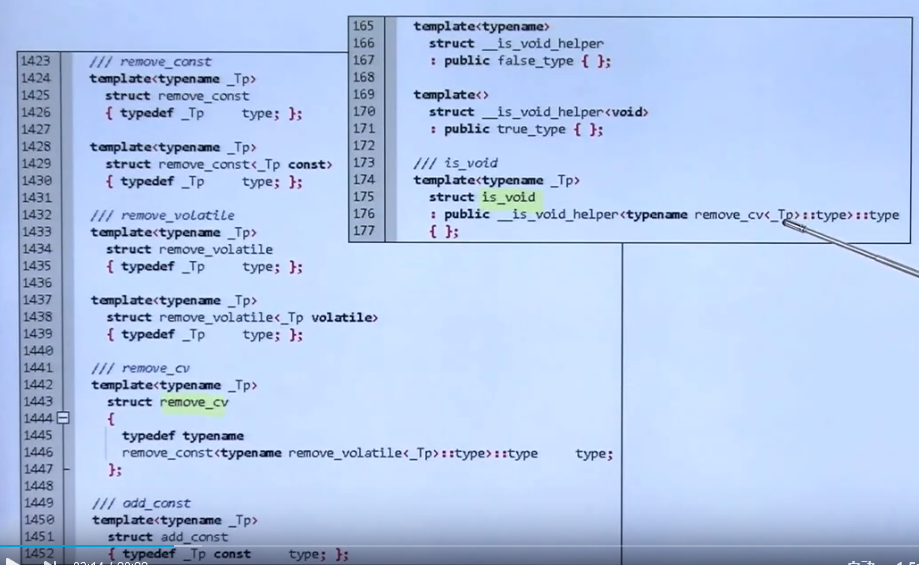
is_integral也类似:

cout
cout是一个对象。

它继承自ostream。对一系列类型做了操作符重载。