MySQL 原理总结
这里主要讨论 InoDB 下的 MySQL。
事务及实现原理
四大特性
- 原子性
- 一致性
- 隔离性
- 持久性
可能出现的问题
-
幻读
一个事务的两次不同时间的相同查询返回了不同的的结果集。例如:一个 select 语句执行了两次,但是在第二次返回了第一次没有返回的行,那么这些行就是“phantom” row。 例如:银行在做统计报表时统计account表中所有用户的总金额时候,此时总共有三个账户,总共金额为3000元,这时候新增了一个用户账户,并且存入1000元,这时候银行再次统计就会发现账户总金额为4000,造成了幻读情况。
-
不可重复读
一个事务内重复读某一行数据,读到的数据不一样。
-
更新丢失
两个事务对同一个数据操作后,一个事务的操作数据丢失。
事务的隔离级别
-
读未提交(Read Uncommited)
如果一个事务已经开始写数据,则另外一个事务则不允许同时进行写操作,但允许其他事务读此行数据。(write mutex)
幻读、不可重复读、更新丢失
-
授权读取(Read Committed)
读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。
不可重复读取和虚读,但避免脏读取。
-
可重复读取(Repeatable Read)(mysql默认级别)
读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。
可能会出现幻读和虚读。
-
序列化(Serializable)
-
未提交读(Read Uncommitted):允许脏读,也就是可能读取到其他会话中未提交事务修改的数据
-
提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)
-
可重复读(Repeated Read):可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻象读
-
串行读(Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞
Innodb
实现架构
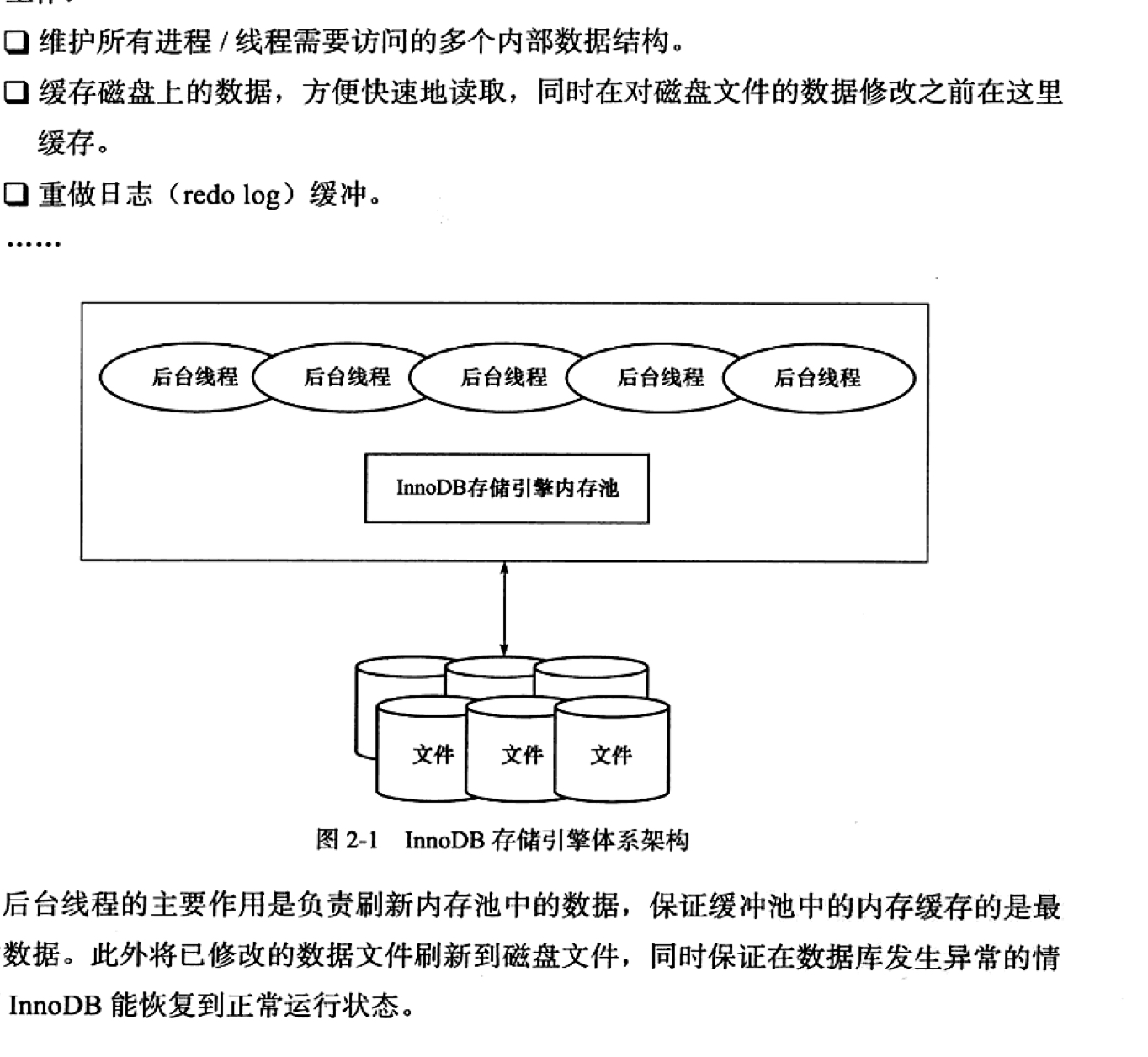
Master线程主要负责把脏数据同步到硬盘,保持数据的一致性。

IO线程主要负责io的回调,read、write、insert buffer、logIO。
Purge线程负责回收过期的redo log。
Page Cleaner负责把对脏页的操作从主线程中分离开来,提高效率。
内存数据对象
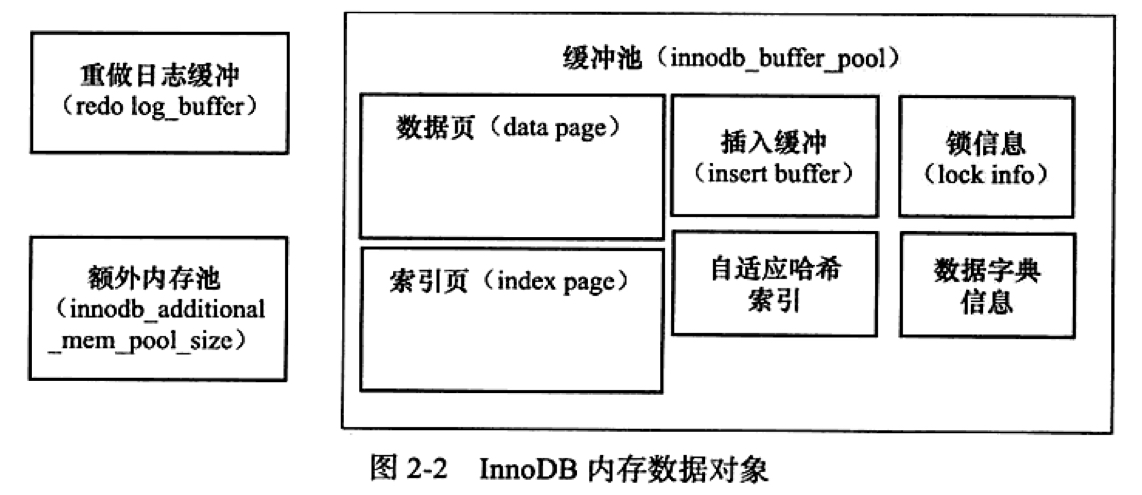
使用LRU算法来缓冲,提高性能。
Checkpoint技术
为了防止数据丢失,事务数据库都采用write ahead log,先写log再写。符合持久化的要求。
Checkpoint技术解决了以下问题:
- 缩短数据库恢复时间
- 缓冲池不够用时,把脏页刷新到硬盘
- 重做日志不可用时,刷新脏页到日志的状态
关键技术
- 插入缓冲
- 两次写
- 自适应哈希索引
- 异步IO
- 刷新邻接页
insert buffer
把多索引的随机访问化为一次性的顺序访问,对机械硬盘性能的影响巨大。
两次写

写时先把脏页复制到dubble write buffer,然后修改完后写到共享表,马上调用fsync同步到硬盘。

自适应哈希 AHI
innodb会自动对能提高性能的列建立哈希索引。
要求:对页的访问模式应该是一样的。
注意哈希搜索只能是等值的,范围不行。
异步IO
区别于同步IO。
刷新邻近页

支持的索引
-
B+索引
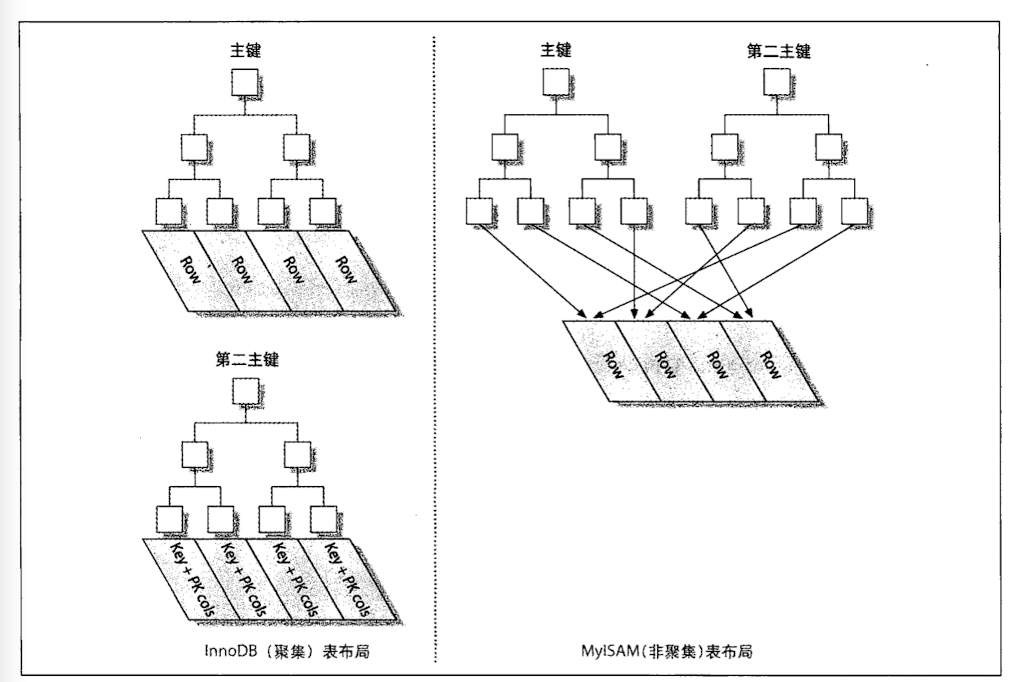
- 聚集索引:实际的数据页在逻辑(双向链表)上按照这个索引来排序。叶子结点存放所有的数据。
- 辅助索引:叶子结点不包含行记录的所有数据,而是包含键值和书签,书签用于导航到表的具体位置。
-
哈希索引
-
全文检索(使用倒排索引实现)
倒排索引有一个持久化的表Auxiliary Table,存放着word。还有一个FTS Index Cache(全文检索索引缓存)用于提高全文检索的性能,内部为红黑树结构。
锁
lock和latch
Innodb中latch可以分为mutex和rwlock。
- lock面向事务,有检测和恢复死锁的机制。表现形式:行锁、表锁、意向锁。
- latch面向线程,保护内存的数据结构,表现形式:读写锁、互斥量。且无检测和恢复死锁的机制。
行级锁
Innodb实现了共享锁(S LOCK)和排他锁(X LOCK)。
同时也支持意向锁。
一致性非锁定读
指Innodb在遇到某个行执行DELETE或者UPDATE操作时,读取操作不会去等待锁的释放,而是读取最近的一个快照数据。
这样极大地提高了数据库的并发性,这是默认的读取方式。
在READ COMMITED和REAPTABLE READ下,Innodb默认都是使用一致性非锁定读的方式。但是区别在于READ COMMITED下读的是最近的一次快照(违反了隔离性),而REAPTABLE READ下读的是事务开始时的快照。
一致性锁定读
数据在修改时,不允许读操作。
外键
外键主要用于引用完整性得约束检查。在InnoDB存储引擎中,对于一个外键列,如果没有显式地对这个列加索引,InnoDB存储引擎自动对其加一个索引,因为这样可以避免表锁。
对于外键值的插入或更新,首先需要查询父表中的记录,即SELECT 父表.但是对于父表的SELECT 操作,不是使用一致性非锁定读的方式,因为这样会发生数据不一致的问题。因此这时使用的是 SELECT …. LOCK IN SHARE MODE 方式,即主动对父表加一个S锁,如果这时父表上已经这样加X锁,子表上的操作会被阻塞。
聚簇索引
联合索引的技巧

联合索引的最左前缀匹配原则介绍_To be a great coder-CSDN博客_最左前缀匹配原则
幻读问题
间隙锁在可重复读隔离级别下才有效。
产生幻读的原因是,行锁只能锁住行,但是新插入记录这个动作,要更新的是记录之间的“间隙”。因此,为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁 (Gap Lock)。
这样,当你执行 select * from t where d=5 for update 的时候,就不止是给数据库中已有的 6 个记录加上了行锁,还同时加了 7 个间隙锁。这样就确保了无法再插入新的记录。
跟间隙锁存在冲突关系的,是“往这个间隙中插入一个记录”这个操作。间隙锁之间都不存在冲突关系。
间隙锁和行锁合称 next-key lock,每个 next-key lock 是前开后闭区间。也就是说,我们的表 t 初始化以后,如果用 select * from t for update 要把整个表所有记录锁起来,就形成了 7 个 next-key lock,分别是 (-∞,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, +supremum]。
注意间隙锁之间可能会引起死锁。
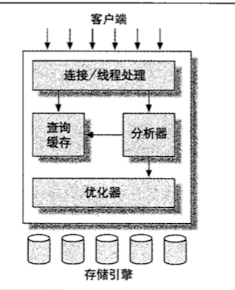
MySQL 概述
逻辑架构
隔离级别
-
读未提交
所有事务可以看到未提交事务的执行结果。
-
读提交
大多数默认隔离级别是读提交,但是 MySQL 不是。读提交满足了隔离的早期定义:一个事务在开始时只能看见已经提交事务所做的改变。一个事务从开始到提交前,所做的任何数据改变是不可见的。
但是存在不可重复读。
-
可重复读
MySQL 的默认隔离级别,但是会产生幻读问题。
幻读指的是,当用户读取一个范围内的数据,会因为另外一个事务在该范围内插入新行,而导致重复读时会出现幻影行。InnoDB 使用 MVCC 多版本并发控制机制解决了这个问题。(这里应该还要搭配间隙锁)
-
可串行化
SERIALIZABLE 是最高的隔离级别,通过强制事务排序,使其不可能冲突。但是会导致大量的锁竞争。
死锁的解决
InnoDB 中可以预知循环相关性,并立即返回错误。目前 InnoDB 处理死锁的方法是,回滚拥有最少排他行级锁的事务。
AUTOCOMMIT
除非显式地开始一个事务,否则它把每一个查询视为一个单独事务。
二阶段锁协议
InnnoDB 使用二阶段锁协议,一个事务在执行的任何过程中都可以得到锁,但是只有在执行 commit 或者 rollback 后才能释放。
显式使用锁定机制:
- SELECT … LOCK IN SHARE MODE
- SELECT … FOR UPDATE
MVCC 多版本并发控制
保证了同个事务的多个实例在运行时看到的都是一致的数据视图。
实现 MVCC 的方式有乐观并发控制、悲观并发控制。
InnoDB 通过给每行数据增加两个隐含值来实现 MVCC,行的创建时间和过期时间。当 可重复读时:

这样的话大多数读操作都不需要加锁。MVCC 仅存在于可重复读和读提交两个隔离级别。
数据引擎
MyISAM
- 不支持事务和行级锁
- 具有全文检索、压缩、空间函数。
- 对整张表进行加锁。
- 支持全文检索
- 延迟更新索引?
InnoDB
- 处理大量短期事务
- 默认在可重复读的基础上加入间隙锁防止幻读。
- 聚簇索引提供快速的主键查找性能,辅助索引(非主键索引)也会包含主键列。
- 内部优化:可预测性的预读,支持在硬盘中 实现提取数据,可适应的哈希索引,自动在内存创建哈希索引,提供插入缓冲区。
- 支持事务和外键。
- MVCC多版本
- 按主键聚合
- 所有索引包含主键列
- 自适应哈希
- 数据装载缓慢
- 阻塞的自动增长
索引
B+索引
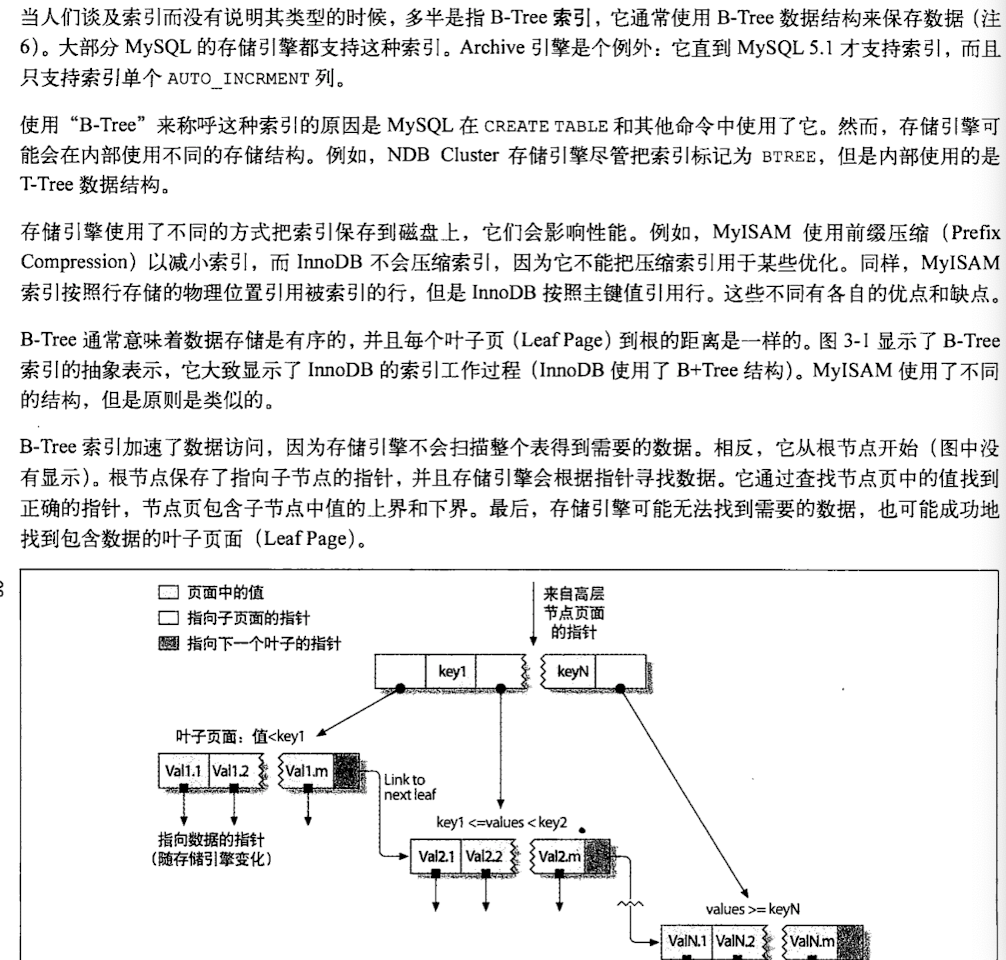

B+索引的局限

哈希索引
只有 Memory 支持显式的哈希索引。
其具有很多局限性:

在 InnoDB 中,有自适应哈希索引,当其注意到一些 索引值被频繁访问时,会在 B+数 的顶端为这些值建立内存中的哈希索引。但是过程是全自动的。

全文索引
是 MyISAM 的特殊索引,无最左适配的局限性。
前缀索引
前缀索引可以节约索引的成本。
聚簇索引(聚集索引)
聚簇索引是在 B+索引的基础上,叶子节点存放实际数据。
B+索引的末端存放的是聚簇索引的 key。

第二索引需要先索引找到聚簇索引的 key,然后再去聚簇索引搜索一次。
覆盖索引
包含所有需要查询的数据列的索引称为覆盖索引。
