警告
这里的实现有很多的 Bug,不能跑通 2B 和 2C 的 Test。
三个函数
相比起 Lab1 的作业,Lab2A 作业量差不多。Lab2A 主要是围绕论文中 Figure2 的选举部分进行实现即可。
首先是有三个控制 Raft 服务器状态的函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
func (rf *Raft) BecomeFollower(term int) {
rf.currentTerm = term
rf.Role = 0
rf.votedFor = -1
rf.GotHeatBeat = false
DPrintf("term %d server %d become Follower\n", term, rf.me)
}
func (rf *Raft) BecomeCandidate() {
rf.votedFor = rf.me
rf.currentTerm++
rf.Role = 1
DPrintf("term %d server %d become Candidate", rf.currentTerm, rf.me)
}
func (rf *Raft) BecomeLeader() {
rf.votedFor = rf.me
rf.Role = 2
for i := 0; i < len(rf.peers); i++ {
rf.MatchIndex[i] = 0
rf.NextIndex[i] = len(rf.log)
}
DPrintf("term %d server %d become Leader", rf.currentTerm, rf.me)
}
|
三个函数负责 server 状态的切换。注意这三个函数都是没有加锁的,需要在调用的地方加锁。
接着是对 Figure2 中需要保存的状态变量进行定义,这里就不放出详细代码了比较简单。最后就是实现 RequestVote 和 AppendEntries。注意需要详细结合 Figure2 里面的策略,否则会出现意想不到的 bug (通常难以解释或者难以自己想出正确的策略)。
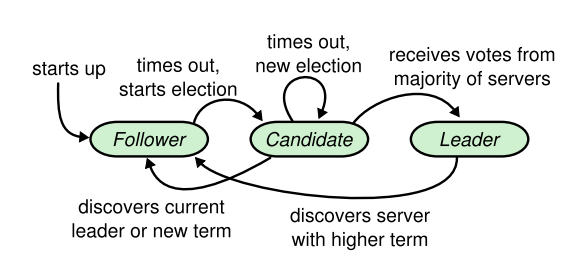
选举相关策略
对所有的 server:
- 若任何通信中发现了
term > currentTerm 的情况,都将所在的 server 设置为 currentTerm = term 的 follower。无论当前 server 是什么角色。
对 followers:
- 回应所有
RPC 请求
- 如果选举定时器超时,仍然没有受到
AppendEntries,则转换为 candidate 开始举行选举投票。
对 candidates:
- 变成 candidate 后开始选举
- 如果收到大部分的选票支持,则成为 Leader。
- 如果收到一个
AppendEntries, 则变成 follower。
- 如果选举超时,则重新开始选举。
对 leader:
- 定时发送
AppendEntries 到所有 server, 防止他们的选举定时器超时。
在我的实现中,大部分的锁都是函数级别的,没有把粒度分得很细。定时器除了使用 for 和 sleep 来实现以外,两个 RPC 的接收也使用了定时器来防止超时,这里的定时器使用 channel 和 select 来实现,可以和 RPC 的接收一起实现,更加简洁。这里给出最核心的 ticker 函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
|
func (rf *Raft) ticker() {
for !rf.killed() {
randomNum := 100 + rand.Intn(100)
time.Sleep(time.Millisecond * time.Duration(randomNum))
rf.mu.Lock()
if !rf.GotHeatBeat && rf.Role == 0 {
rf.BecomeCandidate()
agrees := 1
ch := make(chan RequestVoteReply)
args := RequestVoteArgs{rf.CurrentTerm, rf.me, rf.CommitIndex, rf.CurrentTerm - 1}
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
go rf.sendRequestVote(i, &args, ch)
}
waiting := true
for i := 0; i < len(rf.peers) && waiting; i++ {
if rf.Role != 1 {
break
}
select {
case reply := <-ch:
if reply.VoteGranted {
agrees++
}
if reply.Term > rf.CurrentTerm {
rf.BecomeFollower(reply.Term)
waiting = false
}
case <-time.After(time.Millisecond * 300):
DPrintf("term %d server %d election timeout\n", rf.CurrentTerm, rf.me)
waiting = false
}
if agrees*2 > len(rf.peers) {
break
}
}
if agrees*2 > len(rf.peers) {
rf.BecomeLeader()
} else {
rf.BecomeFollower(rf.CurrentTerm - 1)
}
}
// DPrintf("server %d end first stage\n", rf.me)
rf.GotHeatBeat = false
rf.mu.Unlock()
term, isLeader := rf.GetState()
for isLeader {
ch := make(chan AppendEntriesReply)
args := AppendEntriesArgs{term, rf.me, 0, 0, rf.log, rf.CommitIndex}
for i := 0; i < len(rf.peers); i++ {
go rf.sendAppliedEntries(i, &args, ch)
}
waiting := true
for i := 0; i < len(rf.peers) && waiting; i++ {
// DPrintf("server %d waiting AppendEntriesReply", rf.me)
select{
case reply := <-ch:
// DPrintf("server %d got AppendEntriesReply, term: %d", rf.me, reply.Term)
rf.mu.Lock()
if reply.Term > rf.CurrentTerm {
rf.BecomeFollower(reply.Term)
waiting = false
}
rf.mu.Unlock()
case <- time.After(time.Millisecond * 500):
waiting = false
}
}
time.Sleep(time.Millisecond * 100)
term, isLeader = rf.GetState()
}
}
}
|
结果:
运行 go test -run 2A
1
2
3
4
5
6
7
8
|
Test (2A): initial election ...
... Passed -- 3.1 3 87 21200 0
Test (2A): election after network failure ...
... Passed -- 4.5 3 90 17216 0
Test (2A): multiple elections ...
... Passed -- 7.5 7 625 100826 0
PASS
ok 6.824/raft 15.106s
|
测试通过。