教程地址: https://cstack.github.io/db_tutorial/ 实现一个简化版的数据库。架构设计如下:
Part1 设置REPL(交互式解释器)
“读取-求值-输出”循环(英语:Read-Eval-Print Loop,简称REPL),也被称做交互式顶层构件(英语:interactive toplevel),是一个简单的,交互式的编程环境。这个词常常用于指代一个Lisp的交互式开发环境,也能指代命令行的模式。
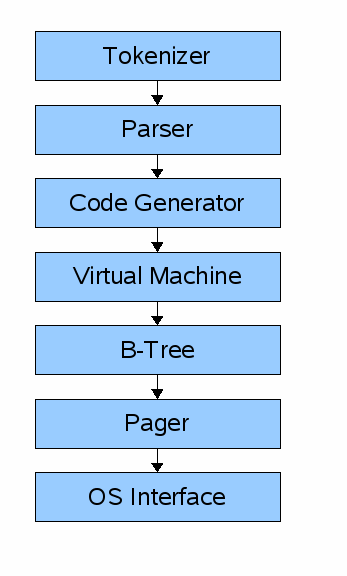
查询路径:Tokenizer->解析器->代码生成器->虚拟机->B树->Pager->操作系统
最简单的REPL环境:
前提知识:
size_t 与 ssize_t类型是为了方便操作系统之间移植的一种计数类型(unsigned_int与signed int).
两者包含在C的stddef.h中和C++的cstddef中(也可不include).
1
2
3
4
5
|
size_t x;
ssize_t y;
printf("%zu\n", x); // prints as unsigned decimal
printf("%zx\n", x); // prints as hex
printf("%zd\n", y); // prints as signed decimal
|
stdlib.h是C标准函数库的头文件,声明了数值与字符串转换函数, 伪随机数生成函数, 动态内存分配函数, 进程控制函数等公共函数。 C++程序应调用等价的 cstdlib 头文件.
C语言的标准函数库中的头文件stdbool.h在C99中引入,包含四个用于布尔型的预定义宏。
IEEE 1003.1-2001标准中的宏定义包括:
bool,会扩展为_Booltrue,会扩展为1false,会扩展为0__bool_true_false_are_defined,会扩展为1
1
|
ssize_t getline(char **lineptr, size_t *n, FILE *stream);
|
REPL demo:
围绕InputBuffer和getline()函数写一个死循环(非完整代码)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
typedef struct
{
char * buffer;
size_t buffer_length;
ssize_t input_length;
}InputBuffer; //buffer
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}
|
Part2 SQL编译器和虚拟机
分成编译器和虚拟机的好处是,虚拟机不需要担心语法上的错误.
修改代码
若语句以.开头,则判断为meta_command 并执行
若判断为普通语句,则,则用prepare_statement来执行语句
这里返回的两个结构体分别为
1
2
3
4
5
6
|
typedef enum {
META_COMMAND_SUCCESS,
META_COMMAND_UNRECOGNIZED_COMMAND
} MetaCommandResult; //meta_command result
typedef enum { PREPARE_SUCCESS, PREPARE_UNRECOGNIZED_STATEMENT } PrepareResult;
|
这里的枚举类型复习一下:
1
2
3
4
5
6
7
8
9
10
11
12
|
enum DAY
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
};
//等价于定义
#define MON 1
#define TUE 2
#define WED 3
#define THU 4
#define FRI 5
#define SAT 6
#define SUN 7
|
这里还牵涉到strncmp的用法
1
|
strncmp(str1,str2,n)==0; //n代表对前n个字符作比较
|
定义了多种状态类型来返回函数状态,且通过strncmp来识别insert操作
这里所谓的编译是非常简化的编译操作(甚至大写的select都无法识别)
Part3 In-Memory,Append-Only,Single-Table Database
目的
现在要创建一个最简单的表格(只能在内存中保存,只能添加数据,只能单表)
插入格式为insert 1 cstack foo@bar.com
表的格式为
|
|
| id |
integer |
| username |
varchar(32) |
| email |
varchar(255) |
这里可以使用sscanf()来检查输入参数
需要知识
关于unit32_t类型,可以查看这篇文章.其包含在stdint.h头文件之中
复习一下宏定义
1
|
#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
|
这相当于定义了一个函数(动态类型).
ROW_SIZE这个常量需要使用这个函数来计算出来(不同操作系统之间不一样).
memcpy()函数:C和C++使用的内存拷贝函数,函数原型为void *memcpy(void *destin, void *source, unsigned n),函数的功能是从源内存地址的起始位置开始拷贝若干个字节到目标内存地址中,即从源source中拷贝n个字节到目标destin中.
实现
步骤:从底层开始实现 先是对Row进行定义,Row的序列化,再定义Table,然后就是寻找Row在Table 的位置.
这里定义了Row的结构体:
1
2
3
4
5
6
7
|
#define COLUMN_USERNAME_SIZE 32
#define COLUMN_EMAIL_SIZE 255
typedef struct {
uint32_t id;
char username[COLUMN_USERNAME_SIZE];
char email[COLUMN_EMAIL_SIZE];
} Row;
|
序列化存储Row(将row放在一个连续的地址中)
|
|
|
| column |
size(bytes) |
offset(起始地址) |
| id |
4 |
0 |
| username |
32 |
4 |
| email |
255 |
36 |
| total |
291 |
|
利用地址来copy内容
1
2
3
4
5
6
7
8
9
10
11
|
void serialize_row(Row* source , void* destination) //序列化
{
memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
}
void deserialize_row(void* source, Row* destination) { //反序列化
memcpy(&(destination->id), source + ID_OFFSET, ID_SIZE);
memcpy(&(destination->username), source + USERNAME_OFFSET, USERNAME_SIZE);
memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
}
|
这里是Table的结构定义
1
2
3
4
5
6
7
8
9
|
const uint32_t PAGE_SIZE = 4096;
#define TABLE_MAX_PAGES 100
const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
typedef struct {
uint32_t num_rows;
void* pages[TABLE_MAX_PAGES]; //用一个大的数组来模拟内存
} Table;
|
接下来找到某一行写入内存的位置(内存->页面->行):
1
2
3
4
5
6
7
8
9
10
11
|
void* row_slot(Table* table, uint32_t row_num) {
uint32_t page_num = row_num / ROWS_PER_PAGE; //页面的序号
void* page = table->pages[page_num]; //切换到当前page
if (page == NULL) {
// 页面为空时申请内存
page = table->pages[page_num] = malloc(PAGE_SIZE);
}
uint32_t row_offset = row_num % ROWS_PER_PAGE; //计算行在页的位置
uint32_t byte_offset = row_offset * ROW_SIZE; //计算以字节计算的行的起始位置
return page + byte_offset; //返回写入地址
}
|
到这里为止,select,insert方法的底层都已经实现完了.
Part4 一些修正与测试
atoi()函数将字符串化为整数
sscanf()函数的缺点在于若输入字符串大于buffer,则会造成溢出.
应该为strtok函数:
1
|
char * strtok ( char * str, const char * delimiters );
|
修正一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
+PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) {
+ statement->type = STATEMENT_INSERT;
+
+ char* keyword = strtok(input_buffer->buffer, " ");
+ char* id_string = strtok(NULL, " ");
+ char* username = strtok(NULL, " ");
+ char* email = strtok(NULL, " ");
+
+ if (id_string == NULL || username == NULL || email == NULL) {
+ return PREPARE_SYNTAX_ERROR;
+ }
+
+ int id = atoi(id_string);
+ if (strlen(username) > COLUMN_USERNAME_SIZE) {
+ return PREPARE_STRING_TOO_LONG;
+ }
+ if (strlen(email) > COLUMN_EMAIL_SIZE) {
+ return PREPARE_STRING_TOO_LONG;
+ }
+
+ statement->row_to_insert.id = id;
+ strcpy(statement->row_to_insert.username, username);
+ strcpy(statement->row_to_insert.email, email);
+
+ return PREPARE_SUCCESS;
+}
+
PrepareResult prepare_statement(InputBuffer* input_buffer,
Statement* statement) {
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+ return prepare_insert(input_buffer, statement);
- statement->type = STATEMENT_INSERT;
- int args_assigned = sscanf(
- input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
- statement->row_to_insert.username, statement->row_to_insert.email);
- if (args_assigned < 3) {
- return PREPARE_SYNTAX_ERROR;
- }
- return PREPARE_SUCCESS;
}
|
还有ID可能为负数的错误.
由于 没安装教程的测试语言,尝试使用shell语言来测试.
- stdin:输入流
- stdout:输出流
- strerr:错误流
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#include <stdio.h>
int main()
{
//printf("please input the value a : \n");
fprintf(stdout, "please input the value a :");
int a ;
//scanf("%d", &a); fscanf的封装
fscanf(stdin, "%d", &a);
if(a<0) {
fprintf(stderr, "the value must > 0 \n");
return 1;
}
return 0;
}
|
C的输入输出流
1
2
3
4
5
6
7
8
|
./main.out > a.txt //覆盖
./main.out >> a.txt //追加
./main.out < input.txt //将input中的内容当做输入流
#1>输出流 2>错误流 <输入流
./main.out 1>stdout.txt 2>stderr.txt <input.txt
|
Part 5 保存数据到硬盘
可以 将Page直接直接拷贝到Database文件中,再定义一个Pager类来通过索引访问相应的page块.
1
2
3
4
5
|
typedef struct{
int file_descriptor;
uint32_t file_length;
void* pages[TABLE_MAX_PAGES];
}Pager;
|
open()函数.
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
lseek():移动文件读写光标
- 欲将读写位置移到文件开头时:lseek(int fildes, 0, SEEK_SET);
- 欲将读写位置移到文件尾时:lseek(int fildes, 0, SEEK_END);
- 想要取得目前文件位置时:lseek(int fildes, 0, SEEK_CUR);
Part 6 The Cursor Abstraction
光标的抽象主要是为了达到以下的目的:
- 创建一个在表开头的光标
- 创建一个在表末尾的光标
- 访问当前光标指向的行
- 移动光标到下一行去
- 删除当前指向的行
- 编辑当前指向的行
- 搜索ID,且定位到相应的行
光标的结构定义为:
1
2
3
4
5
|
typedef struct {
Table* table;
uint32_t row_num;
bool end_of_table; // Indicates a position one past the last element
} Cursor;
|
一切对于虚拟机的操作都可以转化为对光标的抽象操作了